小村のポートフォリオサイト開発(16) データ加工 MD形式に図のURLを埋め込む
こんばんは、小村だよ!
今日も下記のポートフォリオサイトを構築していくよ
- サイト:Little Village
前回APIを利用してUI側にデータ取得するところまで完了しました!
色々やることあるけど、今日はデータ加工を主にやっていきます!
目次
- HTML形式とMD形式の図の共通点を見つける
- 方針決め
- 実装
記録
HTML形式とMD形式の図の共通点を見つける
 |
現状、取得したデータをそのままWebサイトに表示するのに問題があります。
まずWeb内で使用するデータは
内容_MarkDownを使用する予定です。これをちゃんとしたURLにしたものが、HTML形式のものに載ってますね。
というわけで、このURLを抜き出してMarkDown形式側を差替えする必要があります
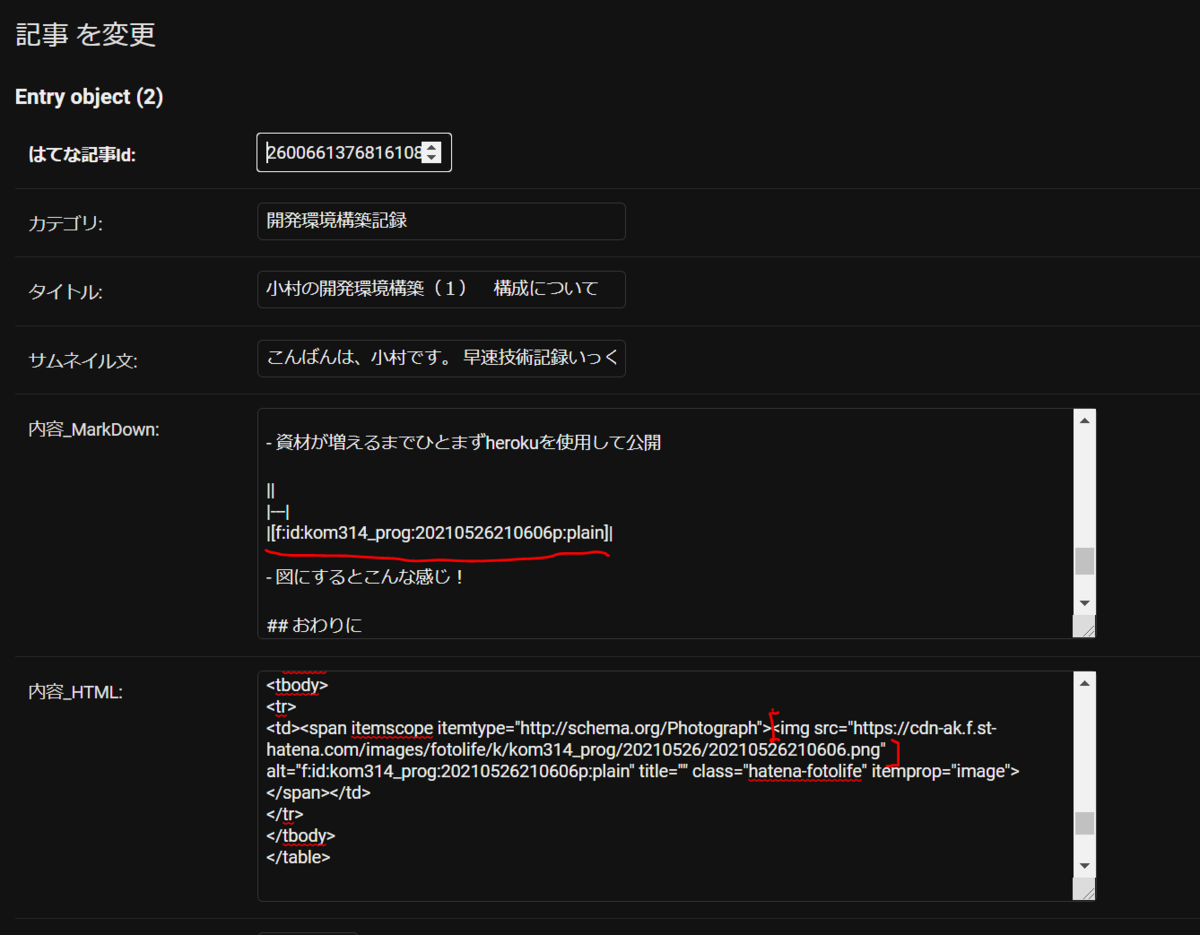
まずは共通点を探すように、見比べてみましょうか
[f:id:kom314_prog:20210526210606p:plain]|
<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/20210526/20210526210606.png" alt="f:id:kom314_prog:20210526210606p:plain" title="" class="hatena-fotolife" itemprop="image">
ふむふむ!!!
何個か比べてみてみましたが、ほとんど共通形式として下記が見つかりました
markdown
頭は右記から始まる
[f:id:kom314_prog:中間の数字はおそらくYYYYMMDDHHmmss
中間の数字の最後のpは拡張子?(pはpng?)
最後は
:plain]|
html
頭は右記から始まる
<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/続きは、YYYYMMDD/YYYYMMDDHHmmss
続きに拡張子 + "
続きに
alt="markdownの文字そのまま"
方針決め
これルールがわかれば、HTMLから取ってこなくてもMarkDownのを書き換えれますね
まずはMarkDownの中で、
[f:id:kom314_prog:の文字を<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/に変換[f:id:kom314_prog:の後ろの14文字の数字を取得し、左から8文字/14文字に変換後ろの
p:plain]を.png">に変換これでひとまず画像のURLを取得できそうですね。
ではコーディングしてみましょう!
実装
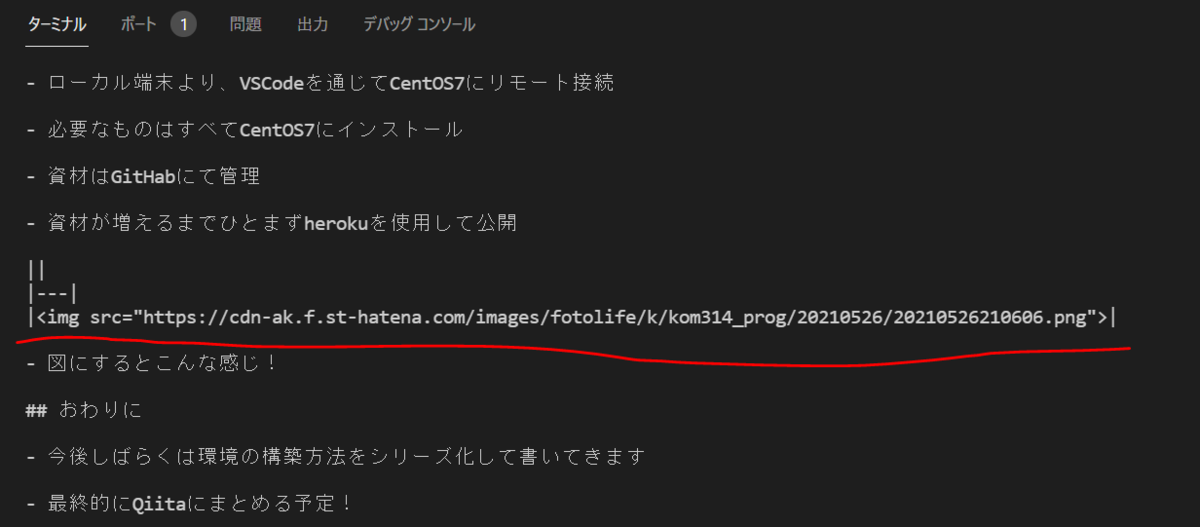 |
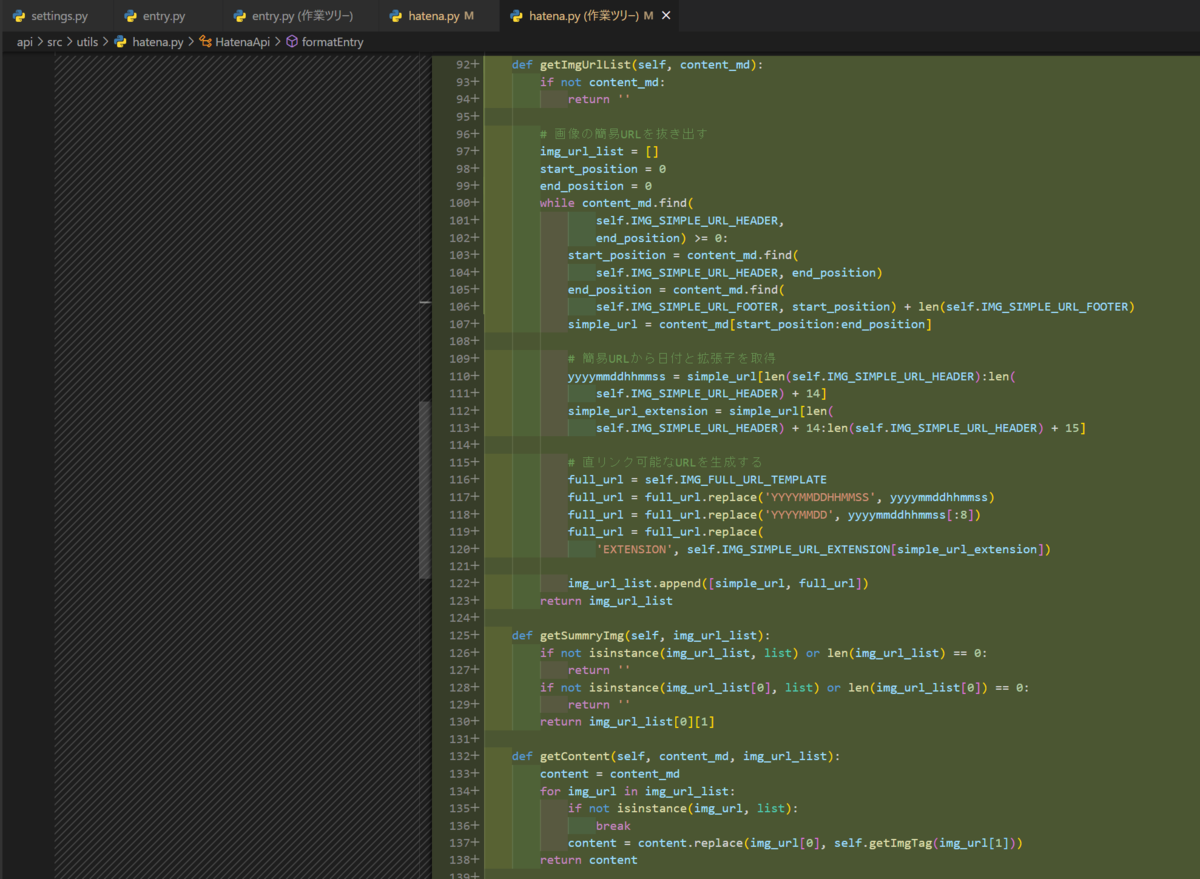
実装完了!
Markdown形式の内容の中の画像のURLが
<img>タグに変換されてますね。最終的にはもっと別の形式に変えるかもしれませんが、ひとまずこれでOK
最終的な修正箇所とソースを張り付けておきます
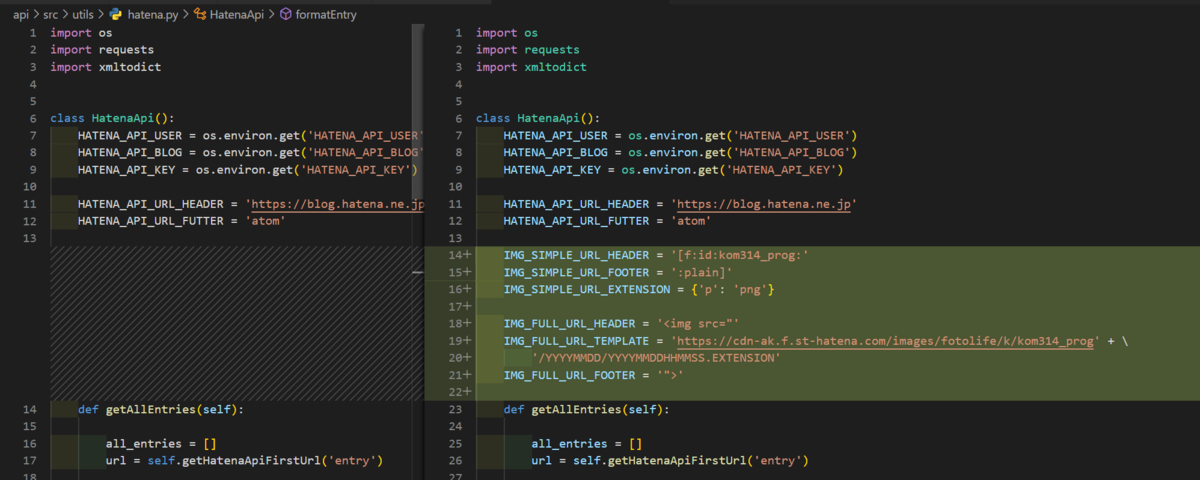 |
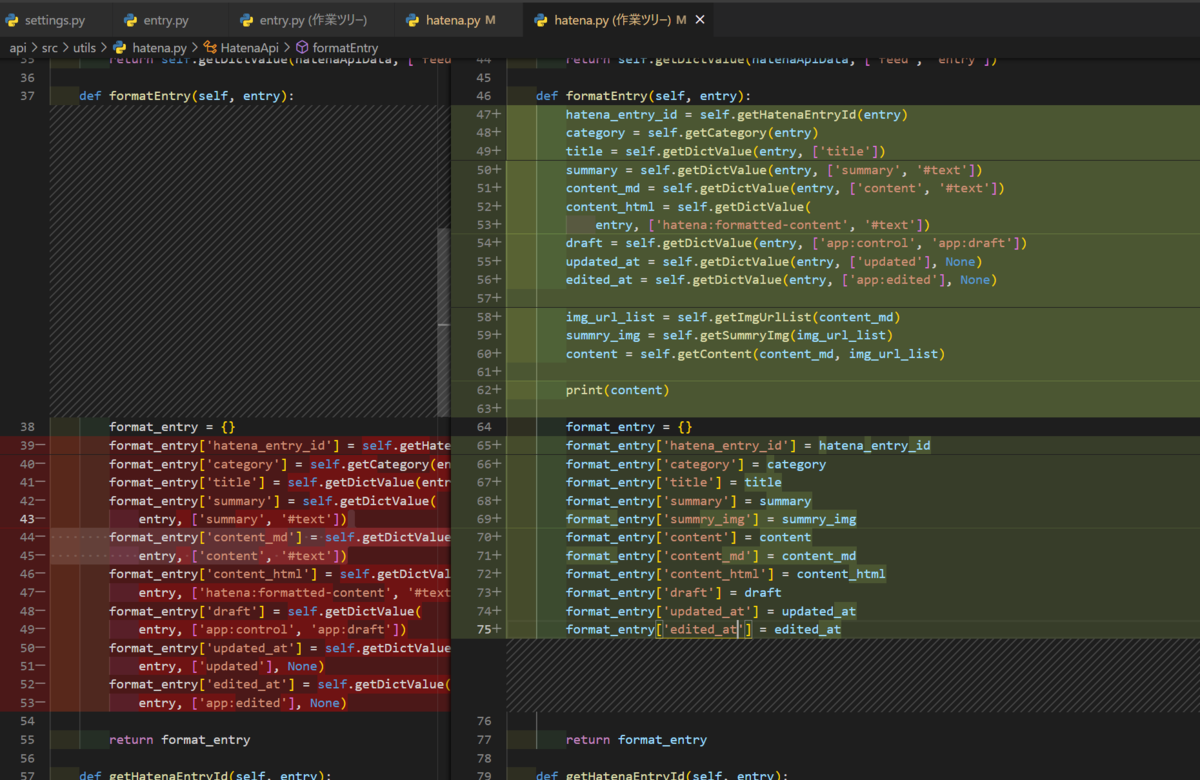 |
 |
import os
import requests
import xmltodict
class HatenaApi():
HATENA_API_USER = os.environ.get('HATENA_API_USER')
HATENA_API_BLOG = os.environ.get('HATENA_API_BLOG')
HATENA_API_KEY = os.environ.get('HATENA_API_KEY')
HATENA_API_URL_HEADER = 'https://blog.hatena.ne.jp'
HATENA_API_URL_FUTTER = 'atom'
IMG_SIMPLE_URL_HEADER = '[f:id:kom314_prog:'
IMG_SIMPLE_URL_FOOTER = ':plain]'
IMG_SIMPLE_URL_EXTENSION = {'p': 'png'}
IMG_FULL_URL_HEADER = '<img src="'
IMG_FULL_URL_TEMPLATE = 'https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog' + \
'/YYYYMMDD/YYYYMMDDHHMMSS.EXTENSION'
IMG_FULL_URL_FOOTER = '">'
def getAllEntries(self):
all_entries = []
url = self.getHatenaApiFirstUrl('entry')
while url != '':
hatenaApiData = self.getHatenaApi(url)
for entry in self.getApiEntries(hatenaApiData):
all_entries.append(self.formatEntry(entry))
url = self.getHatenaApiNextUrl(hatenaApiData)
return all_entries
def getHatenaApi(self, url):
auth = self.getHatenaApiAuth()
hatena_list = requests.get(url, auth=auth)
dict_data = xmltodict.parse(hatena_list.text, encoding='utf-8')
return dict_data
def getApiEntries(self, hatenaApiData):
return self.getDictValue(hatenaApiData, ['feed', 'entry'])
def formatEntry(self, entry):
hatena_entry_id = self.getHatenaEntryId(entry)
category = self.getCategory(entry)
title = self.getDictValue(entry, ['title'])
summary = self.getDictValue(entry, ['summary', '#text'])
content_md = self.getDictValue(entry, ['content', '#text'])
content_html = self.getDictValue(
entry, ['hatena:formatted-content', '#text'])
draft = self.getDictValue(entry, ['app:control', 'app:draft'])
updated_at = self.getDictValue(entry, ['updated'], None)
edited_at = self.getDictValue(entry, ['app:edited'], None)
img_url_list = self.getImgUrlList(content_md)
summry_img = self.getSummryImg(img_url_list)
content = self.getContent(content_md, img_url_list)
print(content)
format_entry = {}
format_entry['hatena_entry_id'] = hatena_entry_id
format_entry['category'] = category
format_entry['title'] = title
format_entry['summary'] = summary
format_entry['summry_img'] = summry_img
format_entry['content'] = content
format_entry['content_md'] = content_md
format_entry['content_html'] = content_html
format_entry['draft'] = draft
format_entry['updated_at'] = updated_at
format_entry['edited_at'] = edited_at
return format_entry
def getHatenaEntryId(self, entry):
id_all = self.getDictValue(entry, ['id'])
id = id_all[id_all.rfind('-') + 1:] if id_all else ''
return id
def getCategory(self, entry):
category_all = self.getDictValue(entry, ['category'])
if isinstance(category_all, list):
category = category_all[0]
else:
category = category_all
return self.getDictValue(category, ['@term'])
def getImgUrlList(self, content_md):
if not content_md:
return ''
# 画像の簡易URLを抜き出す
img_url_list = []
start_position = 0
end_position = 0
while content_md.find(
self.IMG_SIMPLE_URL_HEADER,
end_position) >= 0:
start_position = content_md.find(
self.IMG_SIMPLE_URL_HEADER, end_position)
end_position = content_md.find(
self.IMG_SIMPLE_URL_FOOTER, start_position) + len(self.IMG_SIMPLE_URL_FOOTER)
simple_url = content_md[start_position:end_position]
# 簡易URLから日付と拡張子を取得
yyyymmddhhmmss = simple_url[len(self.IMG_SIMPLE_URL_HEADER):len(
self.IMG_SIMPLE_URL_HEADER) + 14]
simple_url_extension = simple_url[len(
self.IMG_SIMPLE_URL_HEADER) + 14:len(self.IMG_SIMPLE_URL_HEADER) + 15]
# 直リンク可能なURLを生成する
full_url = self.IMG_FULL_URL_TEMPLATE
full_url = full_url.replace('YYYYMMDDHHMMSS', yyyymmddhhmmss)
full_url = full_url.replace('YYYYMMDD', yyyymmddhhmmss[:8])
full_url = full_url.replace(
'EXTENSION', self.IMG_SIMPLE_URL_EXTENSION[simple_url_extension])
img_url_list.append([simple_url, full_url])
return img_url_list
def getSummryImg(self, img_url_list):
if not isinstance(img_url_list, list) or len(img_url_list) == 0:
return ''
if not isinstance(img_url_list[0], list) or len(img_url_list[0]) == 0:
return ''
return img_url_list[0][1]
def getContent(self, content_md, img_url_list):
content = content_md
for img_url in img_url_list:
if not isinstance(img_url, list):
break
content = content.replace(img_url[0], self.getImgTag(img_url[1]))
return content
def getImgTag(self, img_url):
return self.IMG_FULL_URL_HEADER + img_url + self.IMG_FULL_URL_FOOTER
def getHatenaApiFirstUrl(self, action):
url = [
self.HATENA_API_URL_HEADER,
self.HATENA_API_USER,
self.HATENA_API_BLOG,
self.HATENA_API_URL_FUTTER,
action
]
return os.path.join(*url)
def getHatenaApiNextUrl(self, hatenaApiEntries):
url = ''
links = self.getDictValue(hatenaApiEntries, ['feed', 'link'])
if isinstance(links, list):
for link in links:
if self.getDictValue(link, ['@rel']) == 'next':
url = self.getDictValue(link, ['@href'])
return url
def getHatenaApiAuth(self):
return (self.HATENA_API_USER, self.HATENA_API_KEY)
def getDictValue(self, dictData, keys, emptyValue=''):
for key in keys:
if isinstance(dictData, dict):
if key in dictData:
dictData = dictData[key]
else:
return emptyValue
return dictData
おわりに
せっかく今回URL変換したのに、詳細画面を実装してないから最終確認できない!
はやめに詳細画面実装したいなー
ではでは今日はこの辺で!ちゃお~~~!