Qiita:1分で読める プロトタイピングツール AdobeXD のすすめ!
こんばんは!小村だよ!
とある理由で限定公開のQiita記事を書いたので、こっちにも書いちゃいます!
Qiita Slide用に書いたのをそのまま張り付けてるので読みにくいのはごめんね!
目次
- プロトタイピングツールって何?
- Adobe XDの強み
- 類似ツールとの比較
- インストール方法
- 最初にやるべきこと
- プロトタイプを作るには
プロトタイピングツールって何?
- めちゃ簡単にプロトタイプが作れる!
- ↓の画面イメージを10分で作成可能!

Adobe XDの強み
- 無期限無料プランあり!
- 数々のテンプレートが無料で商用利用可!
- ↓類似ツール比較時、日本では1番!
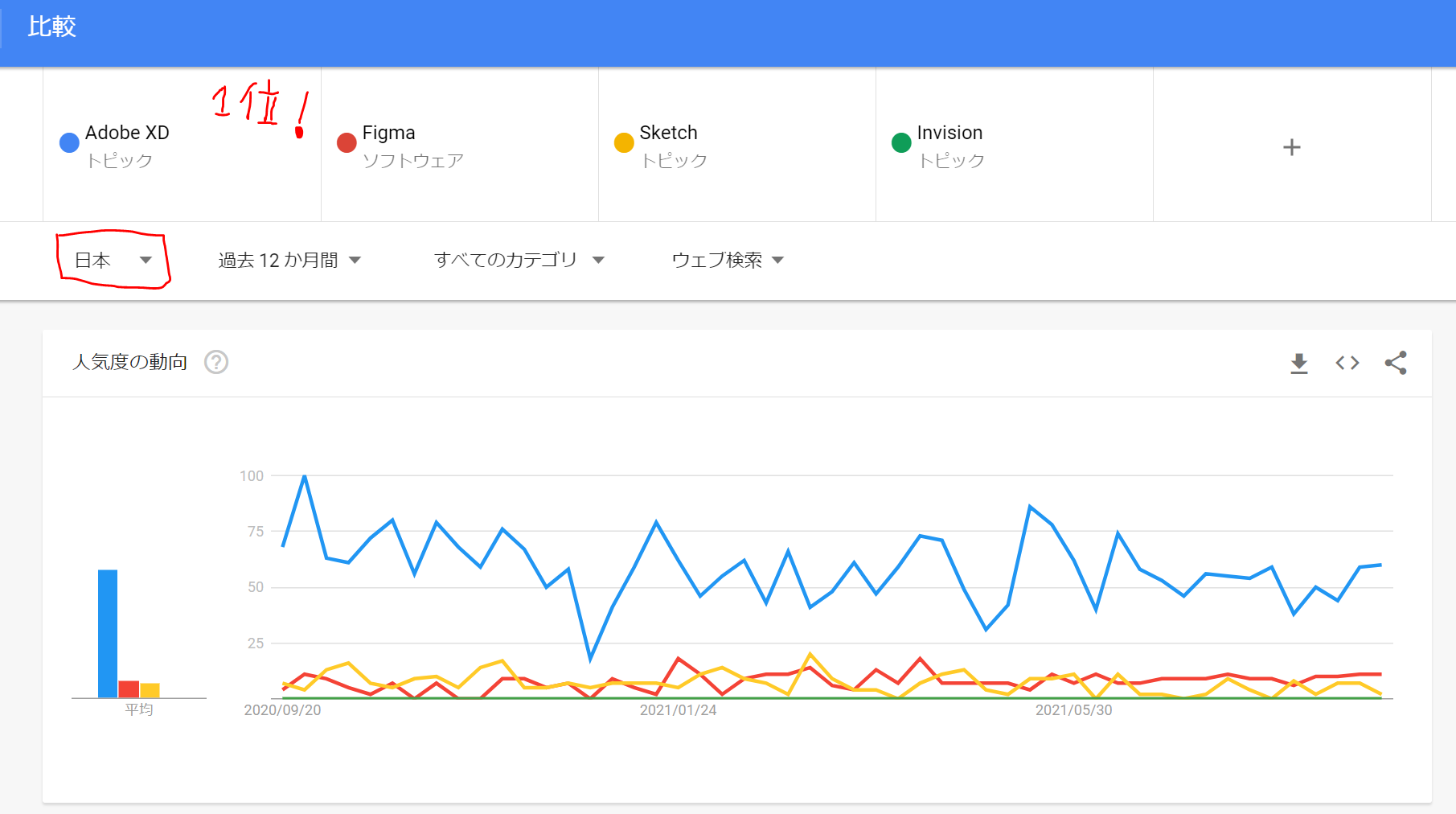
類似ツールとの比較
- 世界で見た時はFigmaが優勢!(下図)
- 今選ぶなら日本語の資料が多いXD!
- 今後の日本のトレンドは要チェック!

インストール方法
- 参考:Adobe XDを無料で使う手順を「画像付き」で解説【期間なし】
- 必ず参考サイトをみながらインストール!
- 公式の無料プランの位置わかりづらい!

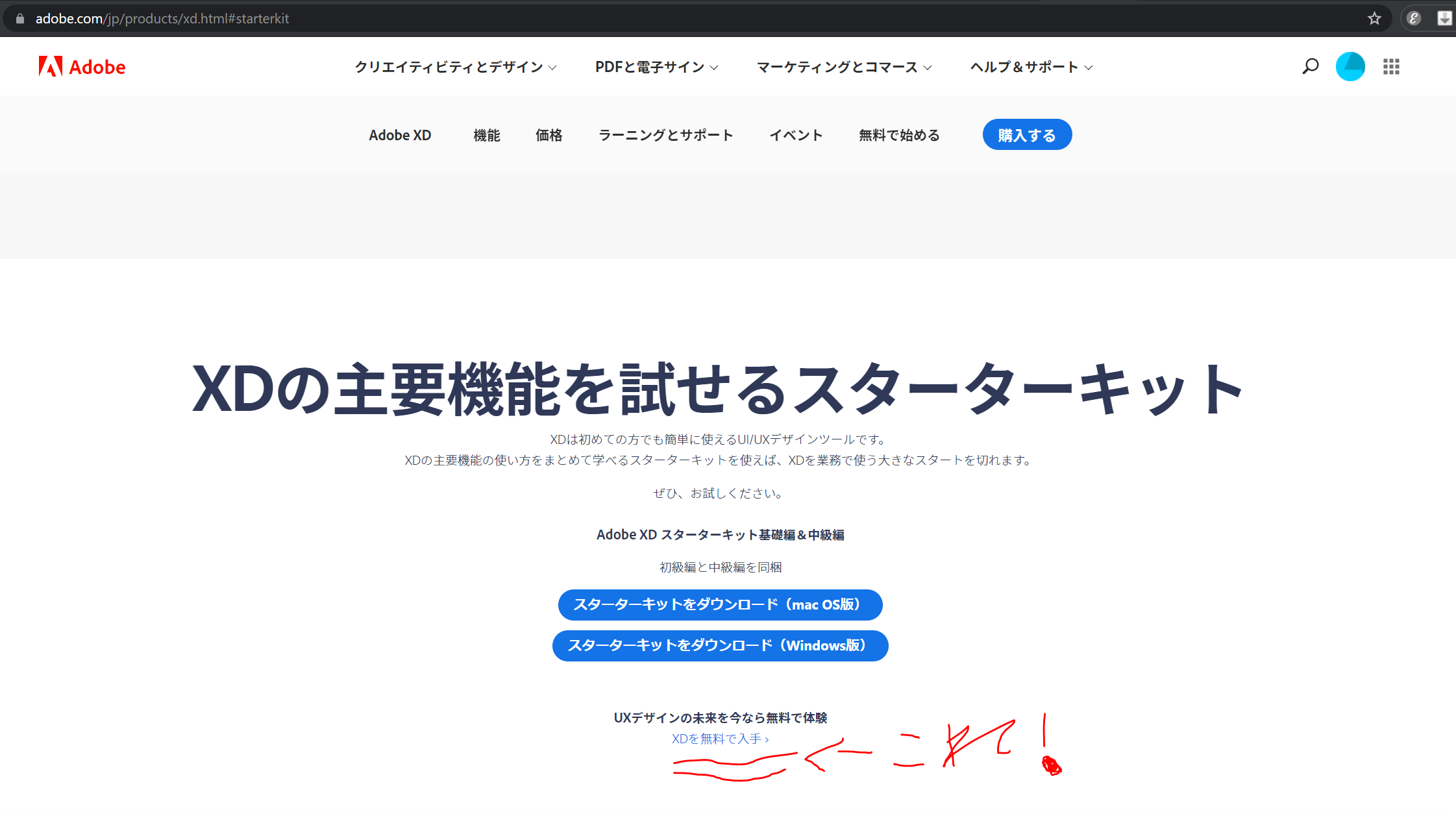
- 公式の無料プランの位置わかりづらい!
最初にやるべきこと
- スターターキットの初級編はやろう!
- 1時間未満で主な使い方の9割がわかる!
- リンク:スターターキット
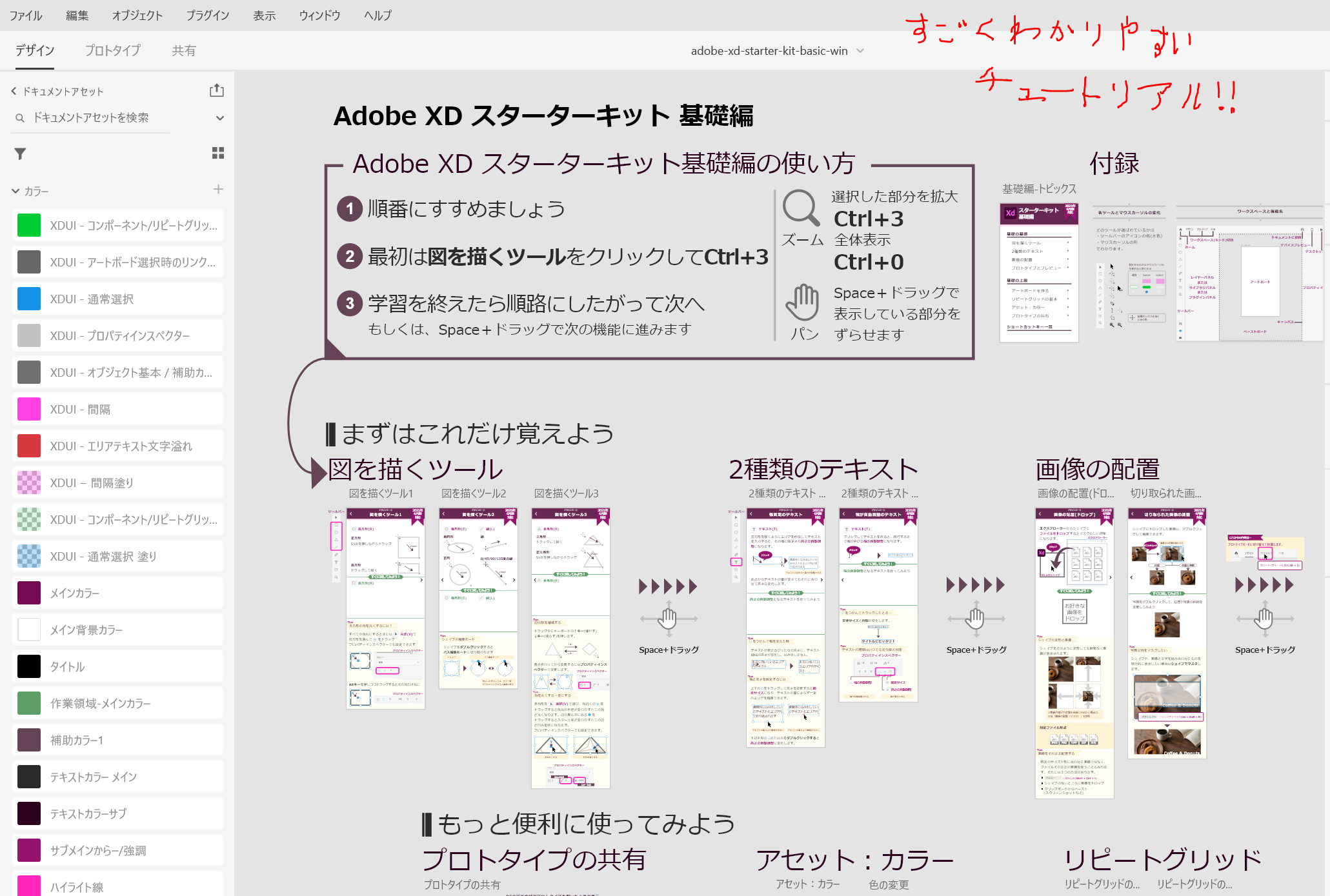
- リンク:スターターキット
プロトタイプを作るには
- 好きなテンプレートをDLしてコピペ!
- 公式にあるのは無料かつ商用利用可!
- 公式UIテンプレート集
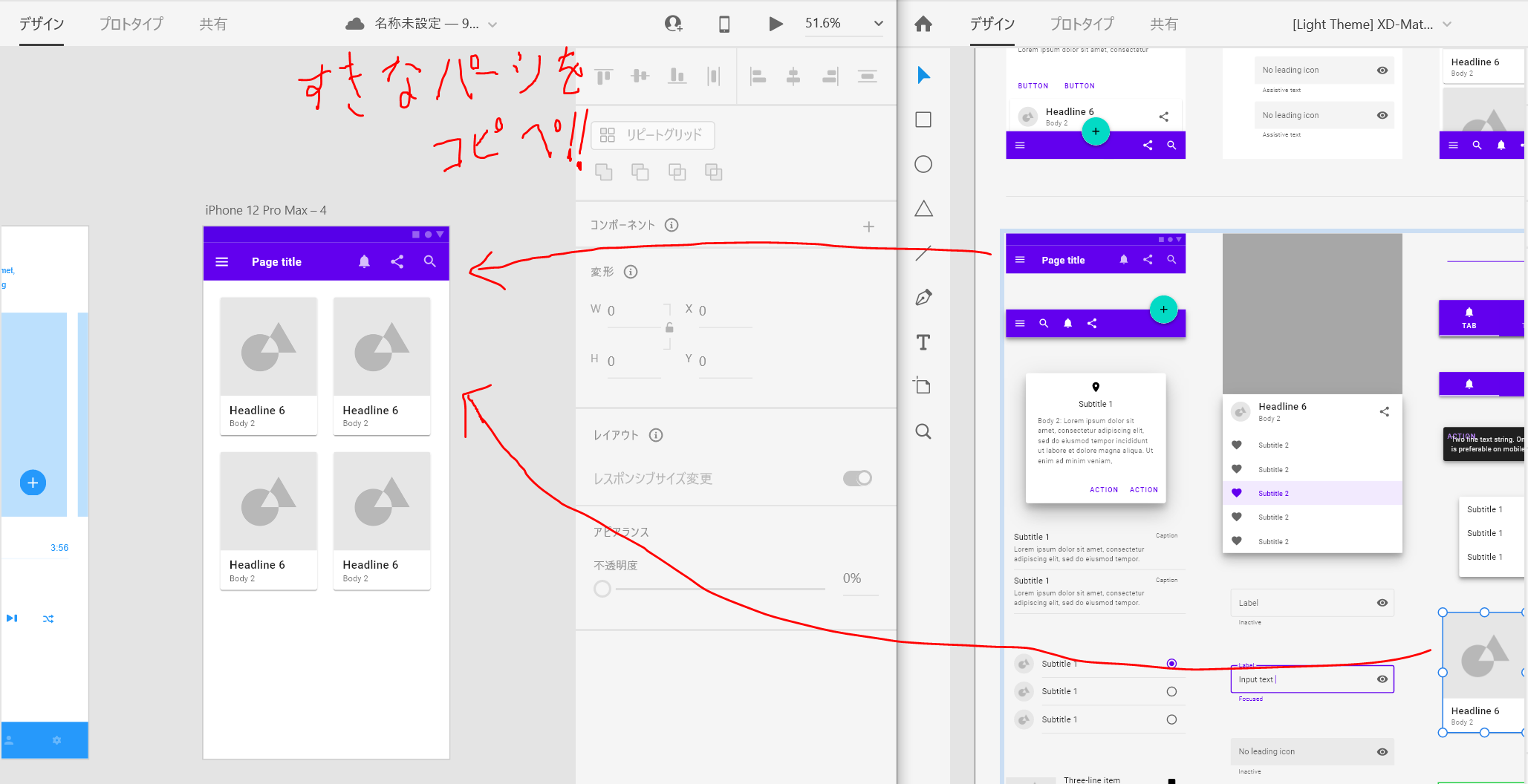
よいプロトタイプ生活を!
調査:モックアップツールの技術選定
こんばんは、小村だよ!
前回にひきつづき調査だよ!
ちょっとしたら、少人数で集まってアプリのモックを作成することになりそう
ひとまずはGoogleSlide使ってつくることになりそうなんだけど
いやこのご時世にスライドでモックアップって……
個人的には物足りないので、いいツール探して提案した~~~い!
というわけでモックアップツールについて調べていきます!
目次
- こだわるポイント
- 条件に合うモックアップツール一覧
- 決定
- XDの使い方を改めて学ぶ
記録
こだわるポイント
モックアップツールを選定するうえで、下記の条件を満たすものを探します
前提
- ひとまずチームは3~5人を想定
必須機能
- 値段が無料、または安くてある程度使える
プラス要素
- ある程度見栄えがよい
- チームで共有するのがたやすい
- 使い方がわかりやすい
条件に合うモックアップツール一覧
下記を参考に、上記の条件に合うものだけ選出します
cacoo(カコー)
月660円/アカウント
無料期間あり:14日間
シンプルで使い方はわかりやすそう
画面遷移図はない
チームで使用するという機能は充実していそう
prott(プロット)
月11100円/3アカウント
無料期間あり:2週間
画面遷移図機能がある(モックの完成度が高い)
チームで使用するという機能は充実していそう
Adobe XD
決定
や、もともとXD使ってたんだけど
改めてほかのとバーッと比べてもさ
めっちゃいいじゃんね!
無料であんだけ使えて、1名までは共有もできるとか破格すぎません???
たいていのモックアップツールは無料期間あるのに無期限て!!
XDでいいじゃんね!!!!
決定!!!文句は聞かん!!!
XDの使い方を改めて学ぶ
今回ついでにめっちゃ良いチュートリアルファイルを見つけた!!
まじで公式太っ腹すぎるね!!!早速DLして遊んでみます!
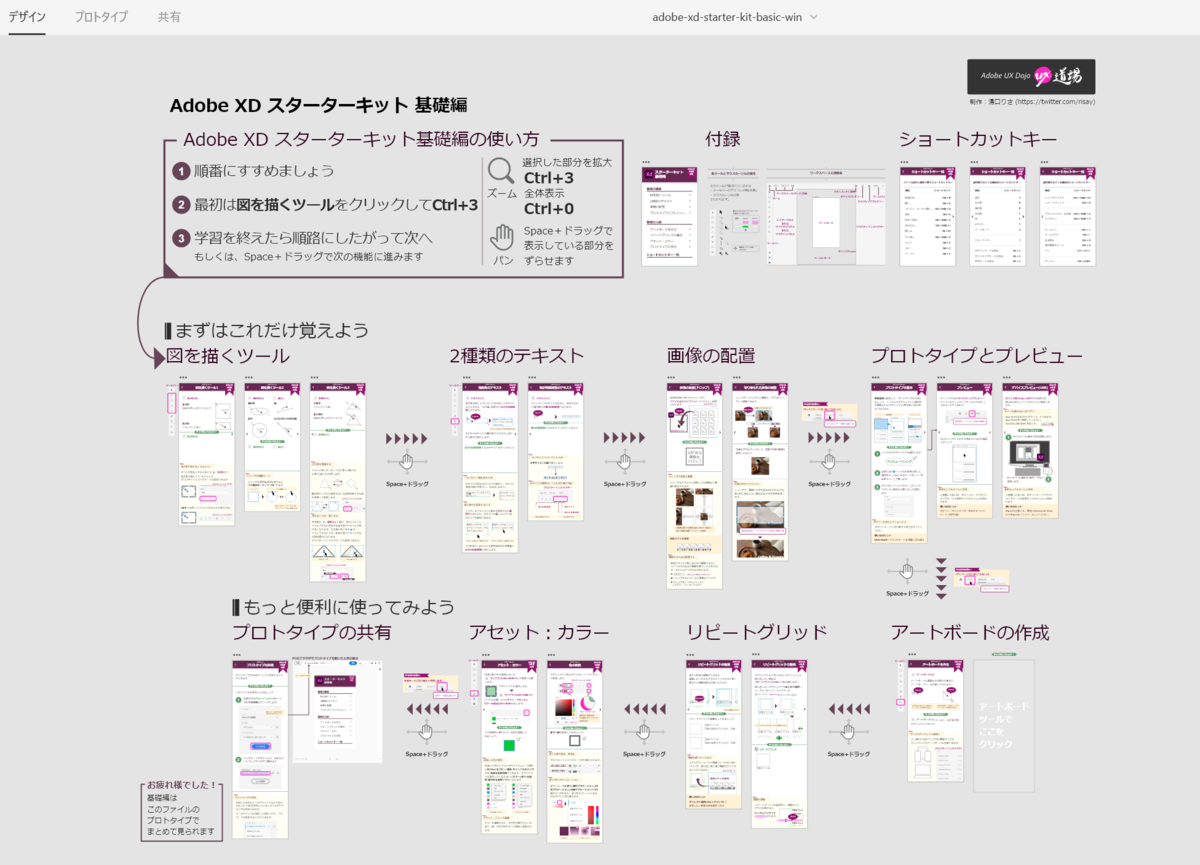 |
遊びました!初級編は全部やってみたよ!
中級編は途中までやってあと通読して完了!
やっぱ直感的でいいですね!AdobeXD!
よかったーーー!これで自信をもってADOBE XDを自信をもって人に勧められます!
おわりに
一通りモックの作り方もちゃんと理解できたので、先導してプロトタイプ作れそう!
まぁデザイン自体は苦手なんですがね。。そこは他の人に託しちゃお
ではでは、ちゃお~~~!
調査:モバイルアプリ開発を作成するうえでの技術選定
こんばんは、小村だよ!
いつかやりたいけど、まだまだ先だなー、他のこと優先しよ!
と考えていたモバイルアプリの作成ですが、なんか急遽やることになりそう!
数か月後には私主導でMVP(Minimum Viable Product)を作成することになりそう!
やばい!!!!!!!やったことない!!!!!なんも知らない!!!
ということで今日は急遽、技術選定をしていくことにします!!!
調査前の予想としては、flutterかreact nativeだけど、どうなるかな~~~
目次
- モバイルアプリの人気言語/フレームワーク調査
- モバイルWEBアプリ
- モバイルネイティブアプリ
- 所感
- Swiftかflutterか
- 結論
記録
モバイルネイティブアプリの人気言語/フレームワーク調査
↑がある程度わかりやすくまとまっていたので、まずはここから必要な情報を抜粋
モバイルWEBアプリ
メリット
- OSアップデートの影響をほぼ受けない
- プラットフォームの審査不要
- WEBで集客できるので集客単価が低い
デメリット
- リアルタイムに弱い
言語/フレームワーク
Javascript:
Vue.js,React,Angular- 今回は上記フレームワークについて割愛するが、さらに詳しい情報として下記有能
所感
Webアプリなら新たな学習が必要あまりなくてうれしいのですが
リアルタイムに弱いのは痛すぎますね……
カメラ機能や通知機能はおそらく使うからなぁ……
モバイルネイティブアプリ
メリット
- リアルタイムな対話が可能
- LTV(顧客生涯価値)向上
デメリット
言語/フレームワーク
iOS:swift
メリット
- iOSに特化していて使いやすい
- Kotlinよりswiftのほうが開発者に人気みたい
デメリット:
Android:Kotlin
両用:React Native(Javascript)
メリット:
- 言語がJavascript
デメリット:
- まだ完全にワンソースで開発することはできない
- カメラなどのos依存箇所の利用方法が弱い
- 大規模なアップデートが必要になったりする
デメリットが多く、今選出する理由はなさそう
両用:Flutter(Dart)
メリット:
- 参考:FlutterでWebRTCをやってみる with AgoraSDK
- OS依存のカメラ操作など、思ってたよりちゃんとできそう
デメリット:
- Dartってどうなのよ???
所感
個人的にSwift、Kotlin、Flutterの3択
iOSを見据えるなら結局Macが必要で、MacBookProを買うかどうかが最大の悩みどころ
MacBookProを買うならSwift or Flutterから選ぶ
ひとまず買わないならKotlinを選ぶ
Macずっとほしいと思ってたから、これをきっかけに買ってしまうべきか悩む!
Swiftかflutterか
Macをもし買うとして、Swift選ぶかFlutter選ぶか悩む~~~
Flutterは想像してたより色々できるみたい。カメラとか通話とかは全然いけそう。
Flutterの選択はありなんだよなーーー。
ただ音楽の機能とかだとまだまだネイティブが必要みたい
初心者にはSwiftかーーーそりゃそうだよなぁ
最初からFlutter使って二兎を追う者は一兎をも得ずになるのありそう
でもなぁ。もともとFlutterには着目してたんだよなぁ
初心者さんが独学でアプリリリースしてるのは励みになりますね。
ただPush通知で大変だったというところをみると、OS依存機能で大変そう
今回機種依存機能めっちゃ使う予定なんだよな~~~となるとSwiftかなーーー
結論
あとは実際Mac買うかどうかなんだけど……
もう決めた!Swiftにしますか!
お金で解決できる悩みはお金で解決する主義です!
あと最後までFlutterと悩みましたが、最初つっかえるとまじで辛そうなので……
まずは作りやすさを優先したいと思います
OS依存機能をフルで使えるのはやはりでかいですね。
Androidに手を出す際に、KotlinではなくFlutterを考慮する方向かな!
おわりに
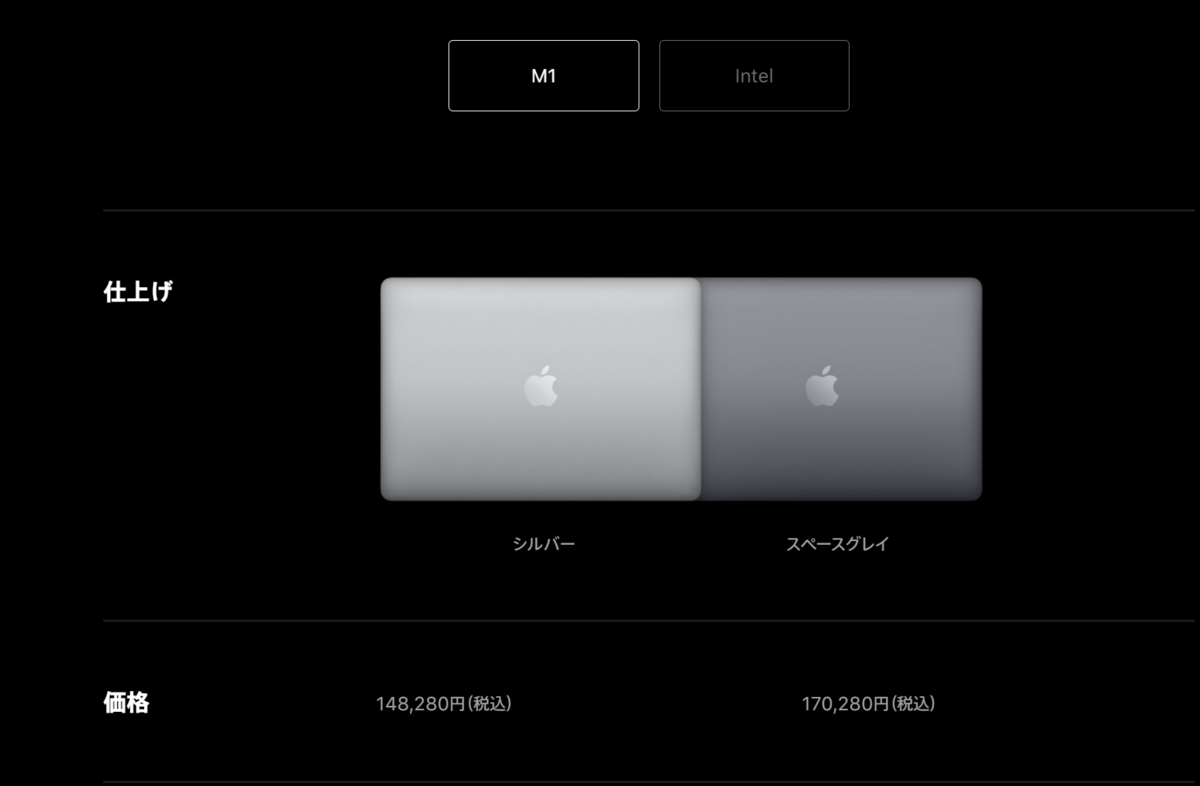 |
買うなら13インチのM1スペースグレイSSD512GBかな!
無駄にしないように頑張っていきたいと思います!
ではでは、ちゃお~~~!
小村のポートフォリオサイト開発(18) ページネーションを追加する(1)
こんばんは、小村だよ!
今日も下記のポートフォリオサイトを構築していくよ
- サイト:Little Village
前回storeを作成したので、今回はその機能を増やしていくよ!
よろしくね!!!
目次
- Entry取得時にページネーションを追加する
- ページ切替処理を追加する
記録
Entry取得時にページネーションを追加する
現状はシンプルに、
api/entriesにアクセスするとDBの全件を取得しますこのままだと今後記事が増えた時に読み込みが大変ですね!
というわけでページネーションを追加していこうと思います。
-
- この参考サイトもシンプルでいいですね
では早速実装していきましょう!
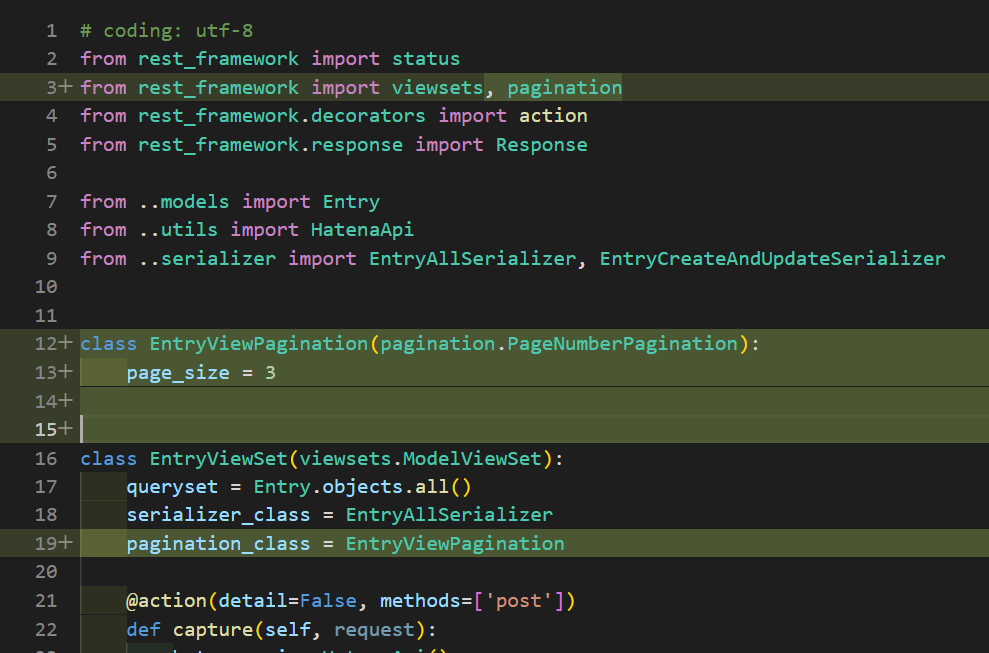 |
ページネーション用のクラスを作成し、デフォルト値を設定します。
あとは
viewにpagination_class = EntryViewPaginationを加えれば完成UIからAPIを呼び出すと下記のようになります
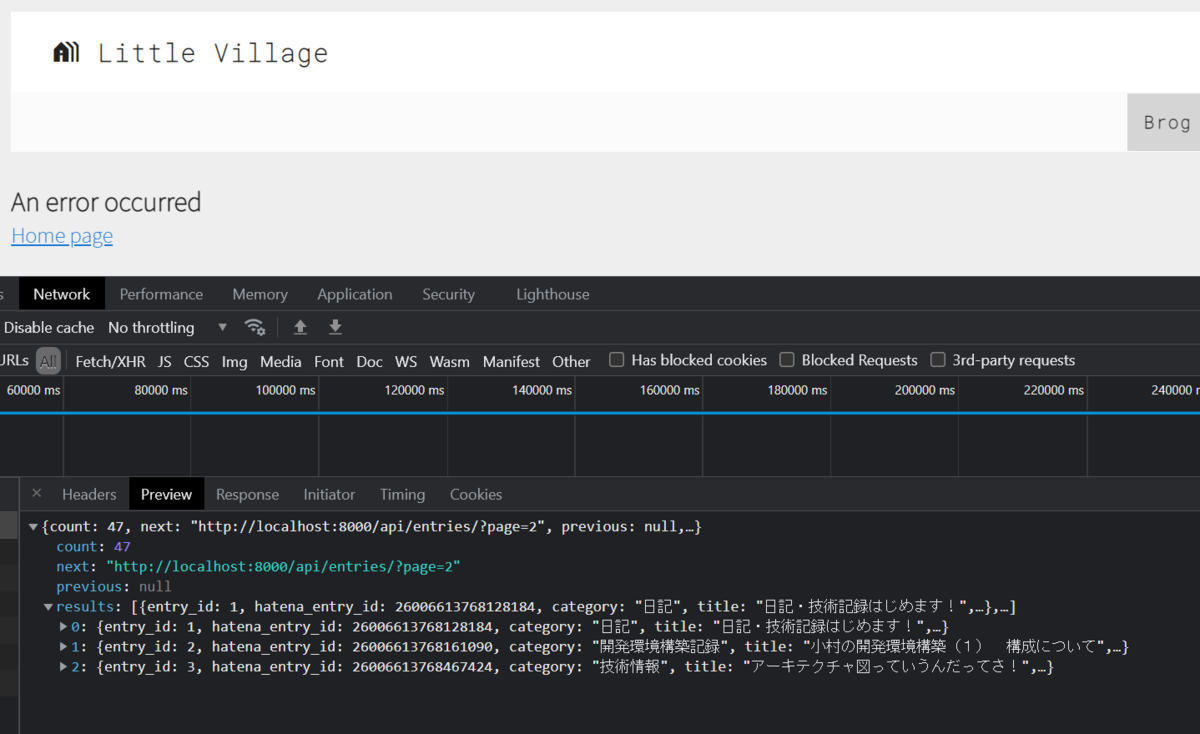 |
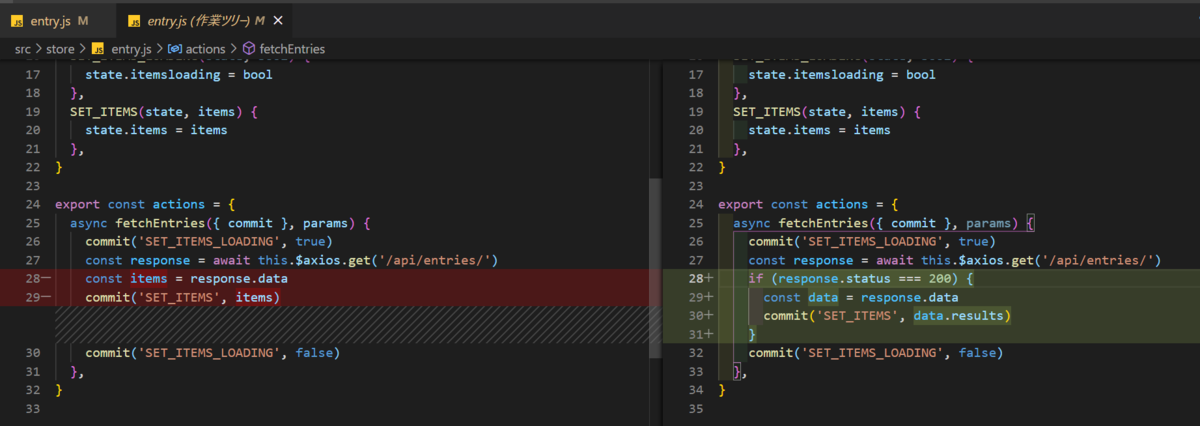
responseに
count,next,previous,resultsが加わりました!返り値が変わったためデータを正しく取得できず、UIがエラーとなってますね
正しく取得してあげましょう!
 |
データの格納場所が
request.dataからrequest.data.resultsに移動しました。これで取得するレコード数がPaginationで定義した数になりましたね。
 |
- 3件だけだと上に寄ってる感がすごいな……
ページ切替処理を追加する
ではページを切り替えられるようにしていきましょう
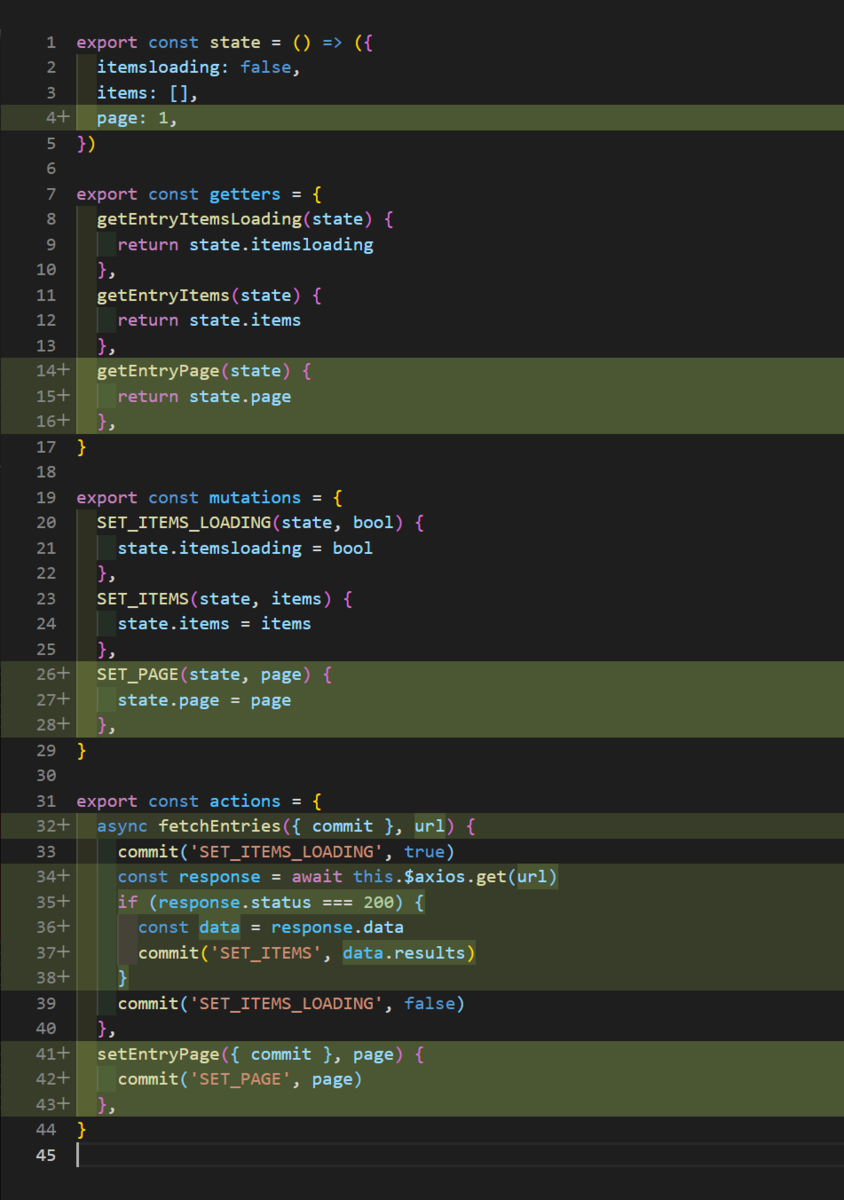
まず、storeのentry.jsに
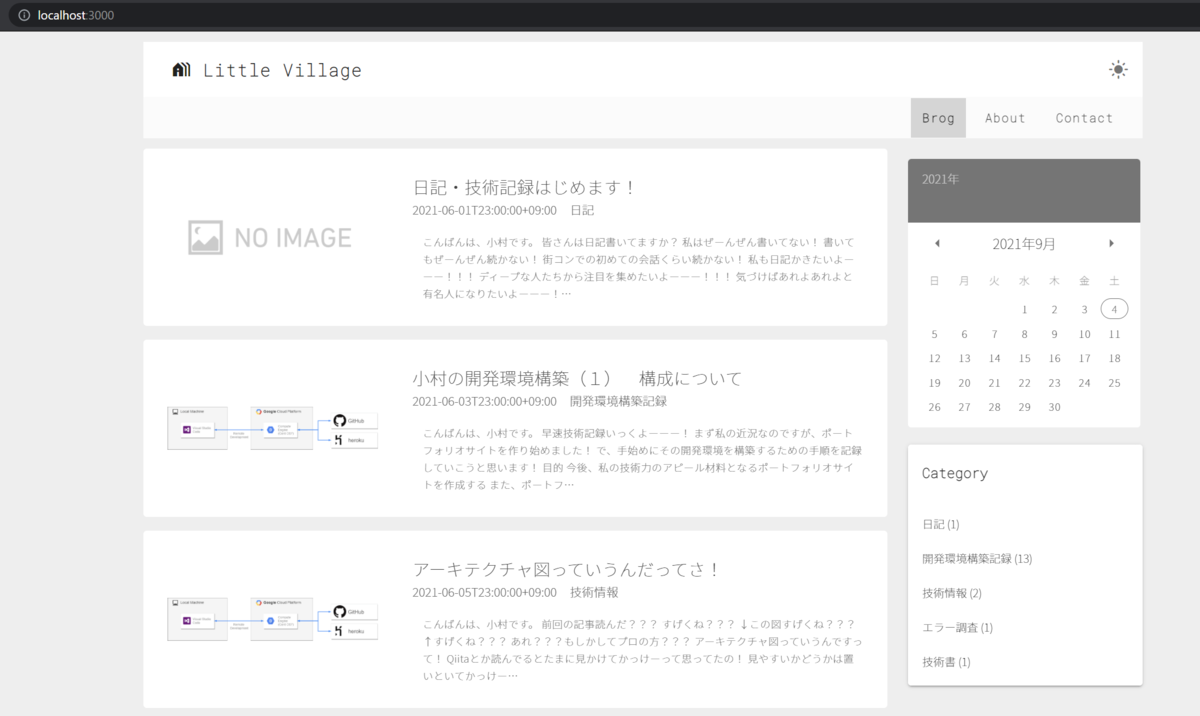
pageを用意して、pageの値を取得、セットするgettars,mutation,actionsを用意しますそれから
fetchEntriesではurlを引数に取るようにしましょうか
 |
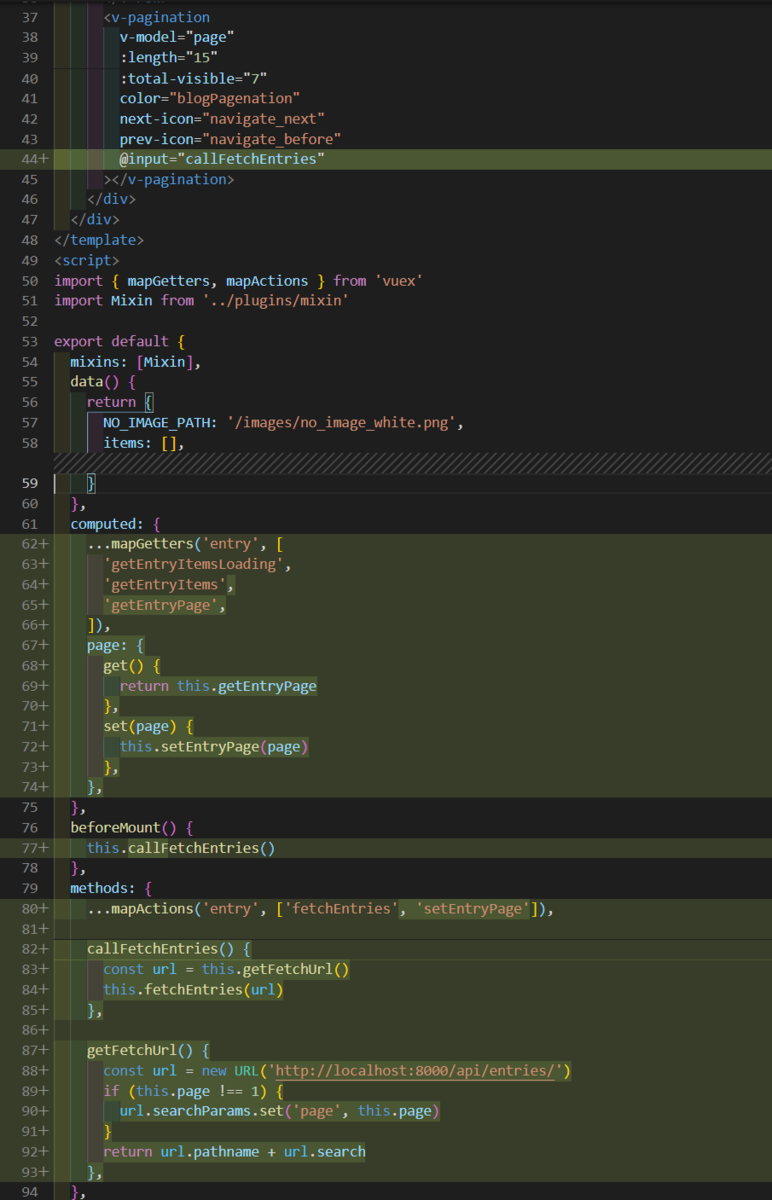
次はコンポーネント側でstoreの
pageを読み書きできるようにしますcomputedに
page:{get(){},set(){}}を記述することで実現できますあとはこのpageの値に応じてURLを変更する
getFetchUrlを用意して<v-pagenation>を操作時に再読み込みする処理を追加すれば完成!
 |
 |
 |
わーい!
ちゃんとページの切替できてますね!
おわりに
まだページ遷移処理は少し残ってます
具体的には、ページネーション数をレコード数に応じて変化させたり
ソート順も降順にしたいですね。最新の記事が手前に欲しい
そのあたりを次回にやりたいとおもいます!
それでは!ちゃおちゃお~~~!
小村のポートフォリオサイト開発(17) API呼び出しをstoreに記述する
こんばんは、小村だよ!
今日も下記のポートフォリオサイトを構築していくよ
- サイト:Little Village
まずはデデン!
 |
サクサクっとサムネイル画像を表示できるようにUIを修正しました。
- 修正箇所は割愛。
画像入るとだいぶそれっぽく見えますねー
今日は何をしようかなーーー
ひとまず今は単純にAPI呼び出ししてますが、今後にそなえてstoreに移動しましょうか。
そうしないと他の箇所で使うときに困ることになりますからねー
目次
- 現状整理
- storeを記述
記録
現状整理
 |
APIの呼び出しなどを1ヵ所で行い、このBrogCardはそこから値を呼び出すのが好ましいです
そこで出てくるのが
storeになりますstoreはvuexの仕組みを適用したNuxt.jsのフォルダになります
storeを記述
では早速書いていきましょうか!
storeでは
state``getter``mutation``actionの4つの要素があります詳しい説明は割愛!基礎なので書籍読もう!
書いた結果がこちら
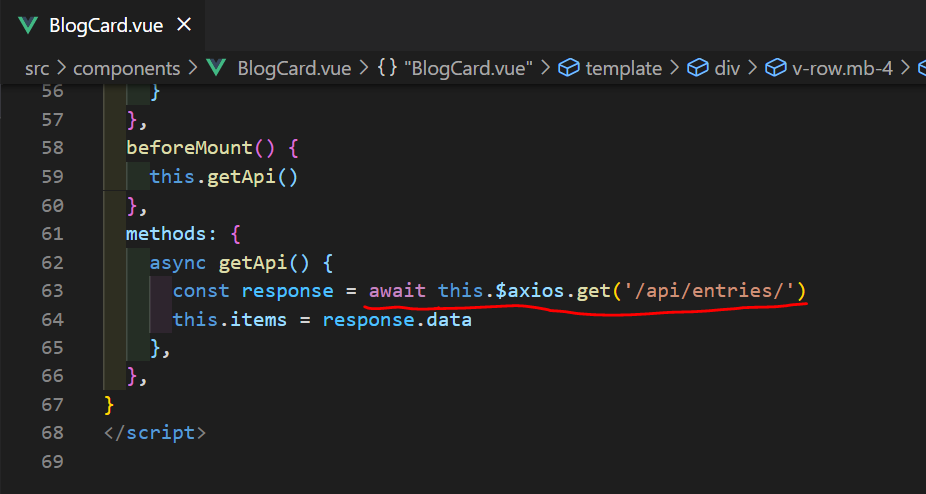
export const state = () => ({
itemsloading: false,
items: [],
})
export const getters = {
getEntryItemsLoading(state) {
return state.itemsloading
},
getEntryItems(state) {
return state.items
},
}
export const mutations = {
SET_ITEMS_LOADING(state, bool) {
state.itemsloading = bool
},
SET_ITEMS(state, items) {
state.items = items
},
}
export const actions = {
async fetchEntries({ commit }, params) {
commit('SET_ITEMS_LOADING', true)
const response = await this.$axios.get('/api/entries/')
const items = response.data
commit('SET_ITEMS', items)
commit('SET_ITEMS_LOADING', false)
},
}
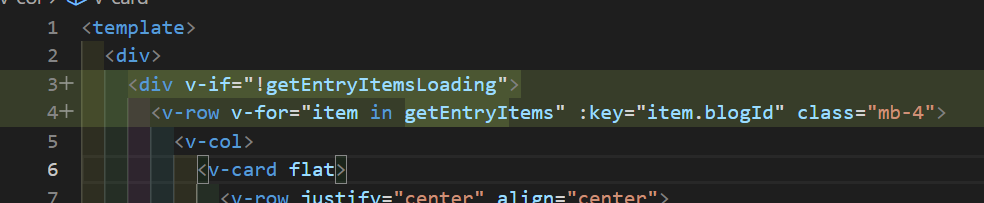
- そしてBlogCard.vueを下記のように修正
 |
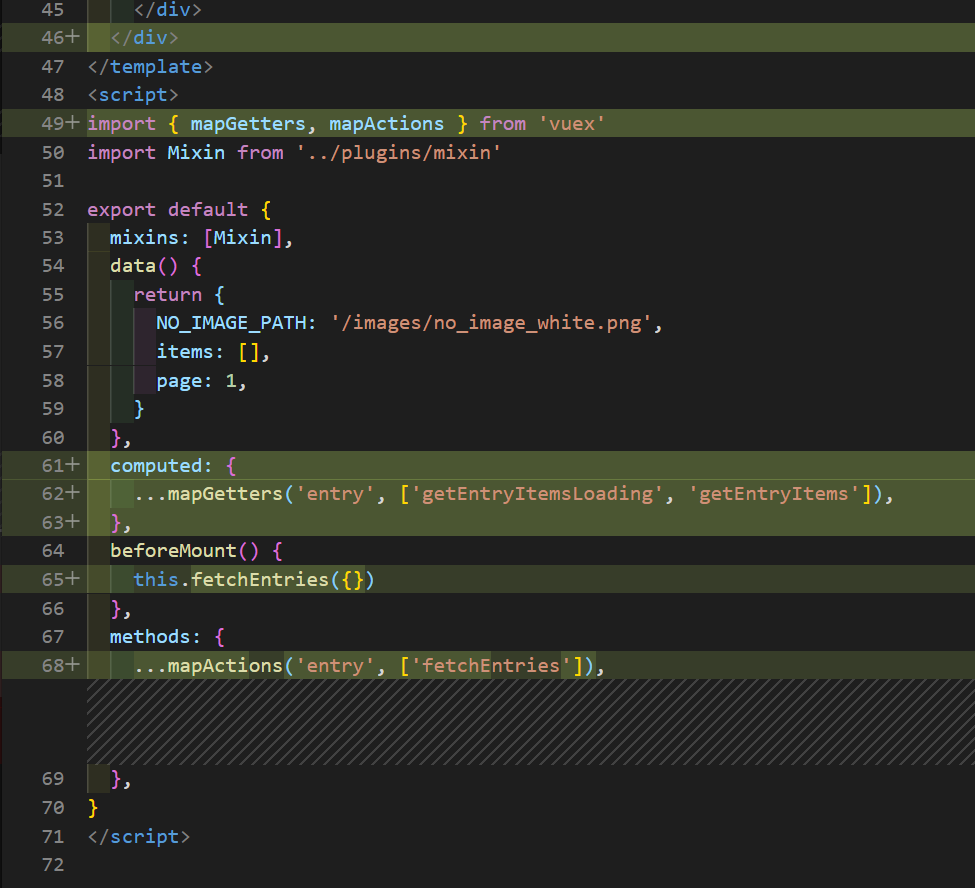 |
このようにして、API呼び出し部分をstoreに記述し、それを呼び出すように変更できました
画面表示は変わっておりません
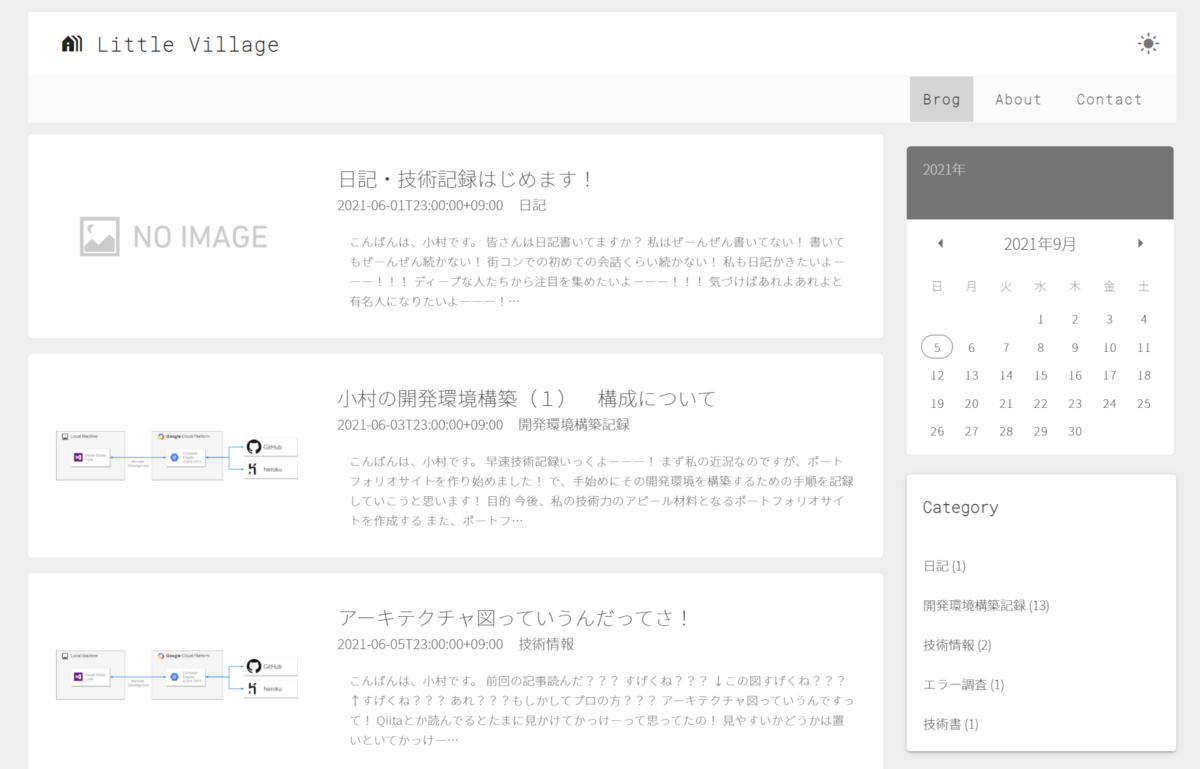 |
注意点として、async awaitでデータを取得しに行っている間にその格納予定の変数を画面から覗くとエラー吐くので、ロード中はアクセスしないようにしましょう!
上図の
<div v-if="!getEntryItemsLoading">がその役割を担ってます
おわりに
基礎と言いながらエラーと戦って数時間かかりました!
業務ではコピペで済ましてた所だったので、改めて自分で調べながら書くと変なところでつまづいたりしますね。
今後は、このstoreを拡張しつつ、ページネーションを作ったりカテゴリをちゃんと表示したりします!
ではでは、ちゃお~~~!
小村のポートフォリオサイト開発(16) データ加工 MD形式に図のURLを埋め込む
こんばんは、小村だよ!
今日も下記のポートフォリオサイトを構築していくよ
- サイト:Little Village
前回APIを利用してUI側にデータ取得するところまで完了しました!
色々やることあるけど、今日はデータ加工を主にやっていきます!
目次
- HTML形式とMD形式の図の共通点を見つける
- 方針決め
- 実装
記録
HTML形式とMD形式の図の共通点を見つける
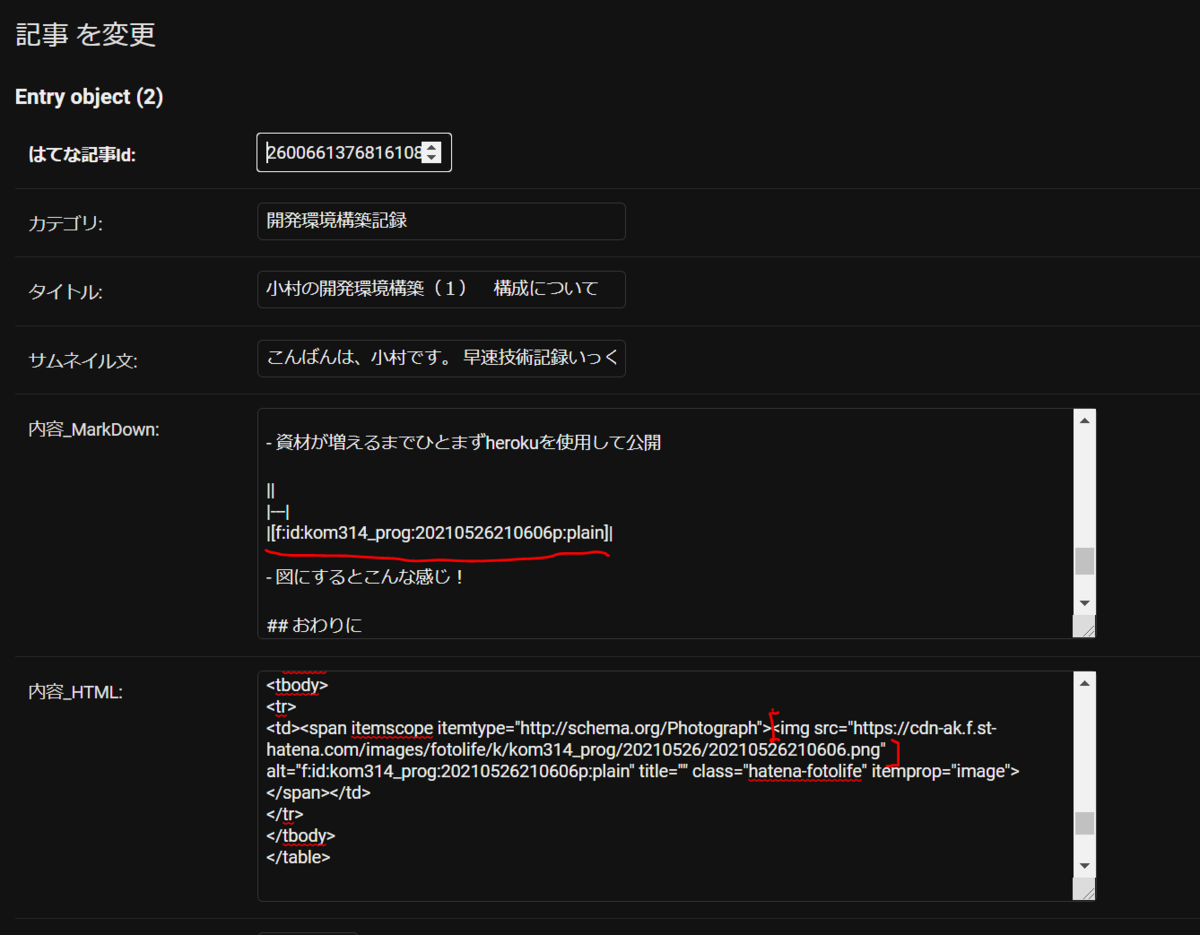 |
現状、取得したデータをそのままWebサイトに表示するのに問題があります。
まずWeb内で使用するデータは
内容_MarkDownを使用する予定です。これをちゃんとしたURLにしたものが、HTML形式のものに載ってますね。
というわけで、このURLを抜き出してMarkDown形式側を差替えする必要があります
まずは共通点を探すように、見比べてみましょうか
[f:id:kom314_prog:20210526210606p:plain]|
<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/20210526/20210526210606.png" alt="f:id:kom314_prog:20210526210606p:plain" title="" class="hatena-fotolife" itemprop="image">
ふむふむ!!!
何個か比べてみてみましたが、ほとんど共通形式として下記が見つかりました
markdown
頭は右記から始まる
[f:id:kom314_prog:中間の数字はおそらくYYYYMMDDHHmmss
中間の数字の最後のpは拡張子?(pはpng?)
最後は
:plain]|
html
頭は右記から始まる
<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/続きは、YYYYMMDD/YYYYMMDDHHmmss
続きに拡張子 + "
続きに
alt="markdownの文字そのまま"
方針決め
これルールがわかれば、HTMLから取ってこなくてもMarkDownのを書き換えれますね
まずはMarkDownの中で、
[f:id:kom314_prog:の文字を<img src="https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog/に変換[f:id:kom314_prog:の後ろの14文字の数字を取得し、左から8文字/14文字に変換後ろの
p:plain]を.png">に変換これでひとまず画像のURLを取得できそうですね。
ではコーディングしてみましょう!
実装
 |
実装完了!
Markdown形式の内容の中の画像のURLが
<img>タグに変換されてますね。最終的にはもっと別の形式に変えるかもしれませんが、ひとまずこれでOK
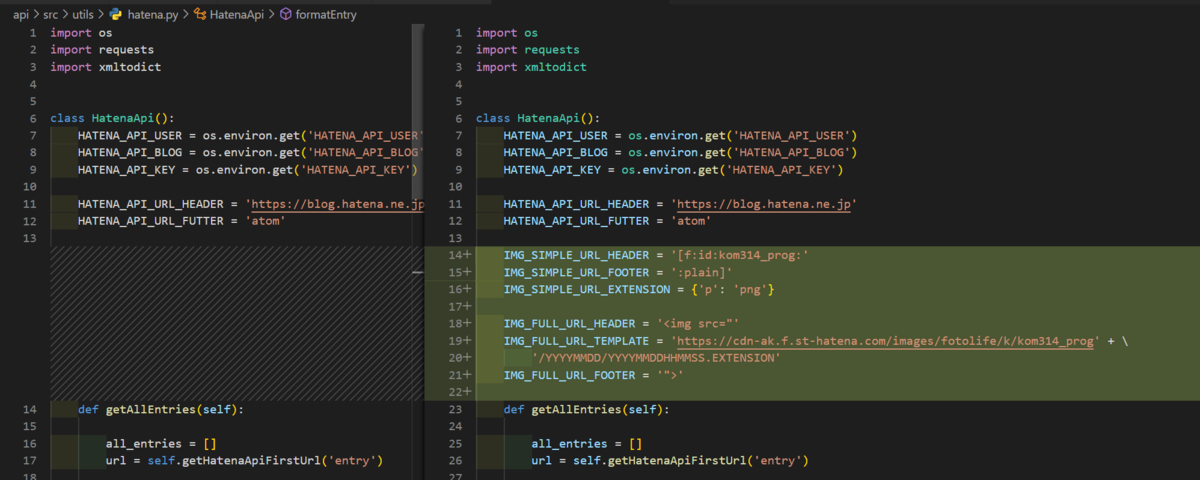
最終的な修正箇所とソースを張り付けておきます
 |
 |
 |
import os
import requests
import xmltodict
class HatenaApi():
HATENA_API_USER = os.environ.get('HATENA_API_USER')
HATENA_API_BLOG = os.environ.get('HATENA_API_BLOG')
HATENA_API_KEY = os.environ.get('HATENA_API_KEY')
HATENA_API_URL_HEADER = 'https://blog.hatena.ne.jp'
HATENA_API_URL_FUTTER = 'atom'
IMG_SIMPLE_URL_HEADER = '[f:id:kom314_prog:'
IMG_SIMPLE_URL_FOOTER = ':plain]'
IMG_SIMPLE_URL_EXTENSION = {'p': 'png'}
IMG_FULL_URL_HEADER = '<img src="'
IMG_FULL_URL_TEMPLATE = 'https://cdn-ak.f.st-hatena.com/images/fotolife/k/kom314_prog' + \
'/YYYYMMDD/YYYYMMDDHHMMSS.EXTENSION'
IMG_FULL_URL_FOOTER = '">'
def getAllEntries(self):
all_entries = []
url = self.getHatenaApiFirstUrl('entry')
while url != '':
hatenaApiData = self.getHatenaApi(url)
for entry in self.getApiEntries(hatenaApiData):
all_entries.append(self.formatEntry(entry))
url = self.getHatenaApiNextUrl(hatenaApiData)
return all_entries
def getHatenaApi(self, url):
auth = self.getHatenaApiAuth()
hatena_list = requests.get(url, auth=auth)
dict_data = xmltodict.parse(hatena_list.text, encoding='utf-8')
return dict_data
def getApiEntries(self, hatenaApiData):
return self.getDictValue(hatenaApiData, ['feed', 'entry'])
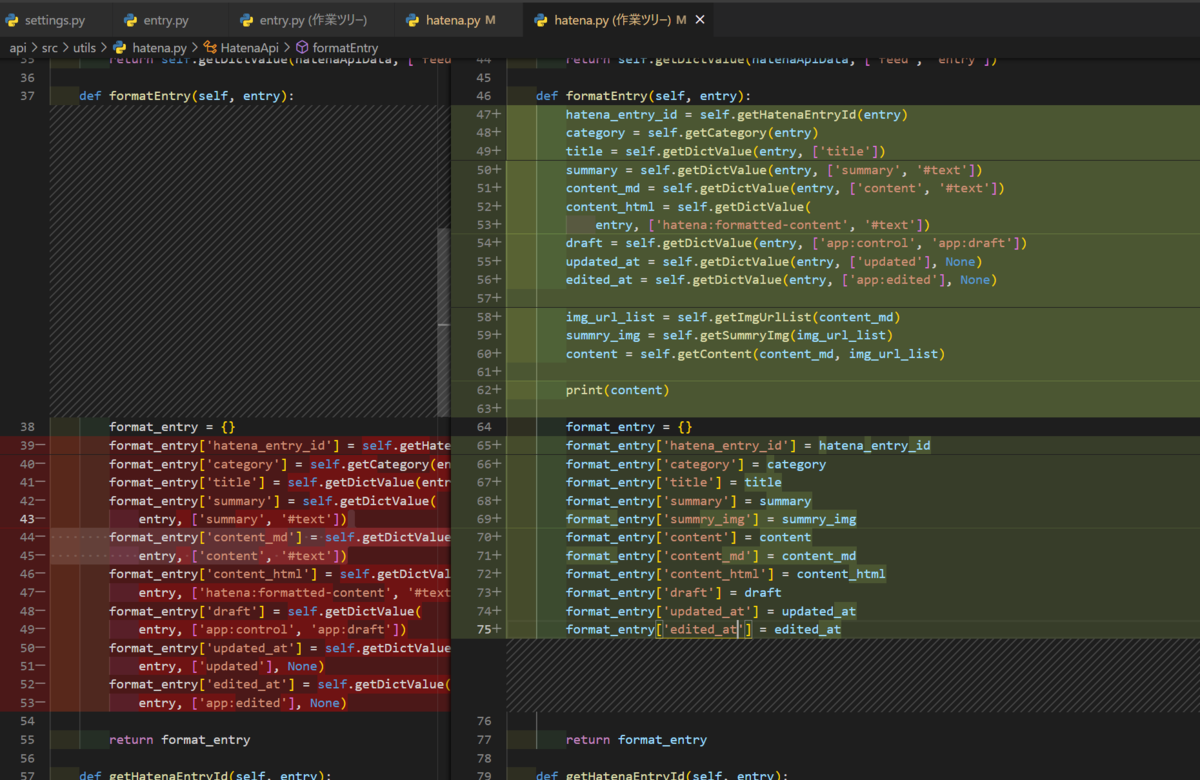
def formatEntry(self, entry):
hatena_entry_id = self.getHatenaEntryId(entry)
category = self.getCategory(entry)
title = self.getDictValue(entry, ['title'])
summary = self.getDictValue(entry, ['summary', '#text'])
content_md = self.getDictValue(entry, ['content', '#text'])
content_html = self.getDictValue(
entry, ['hatena:formatted-content', '#text'])
draft = self.getDictValue(entry, ['app:control', 'app:draft'])
updated_at = self.getDictValue(entry, ['updated'], None)
edited_at = self.getDictValue(entry, ['app:edited'], None)
img_url_list = self.getImgUrlList(content_md)
summry_img = self.getSummryImg(img_url_list)
content = self.getContent(content_md, img_url_list)
print(content)
format_entry = {}
format_entry['hatena_entry_id'] = hatena_entry_id
format_entry['category'] = category
format_entry['title'] = title
format_entry['summary'] = summary
format_entry['summry_img'] = summry_img
format_entry['content'] = content
format_entry['content_md'] = content_md
format_entry['content_html'] = content_html
format_entry['draft'] = draft
format_entry['updated_at'] = updated_at
format_entry['edited_at'] = edited_at
return format_entry
def getHatenaEntryId(self, entry):
id_all = self.getDictValue(entry, ['id'])
id = id_all[id_all.rfind('-') + 1:] if id_all else ''
return id
def getCategory(self, entry):
category_all = self.getDictValue(entry, ['category'])
if isinstance(category_all, list):
category = category_all[0]
else:
category = category_all
return self.getDictValue(category, ['@term'])
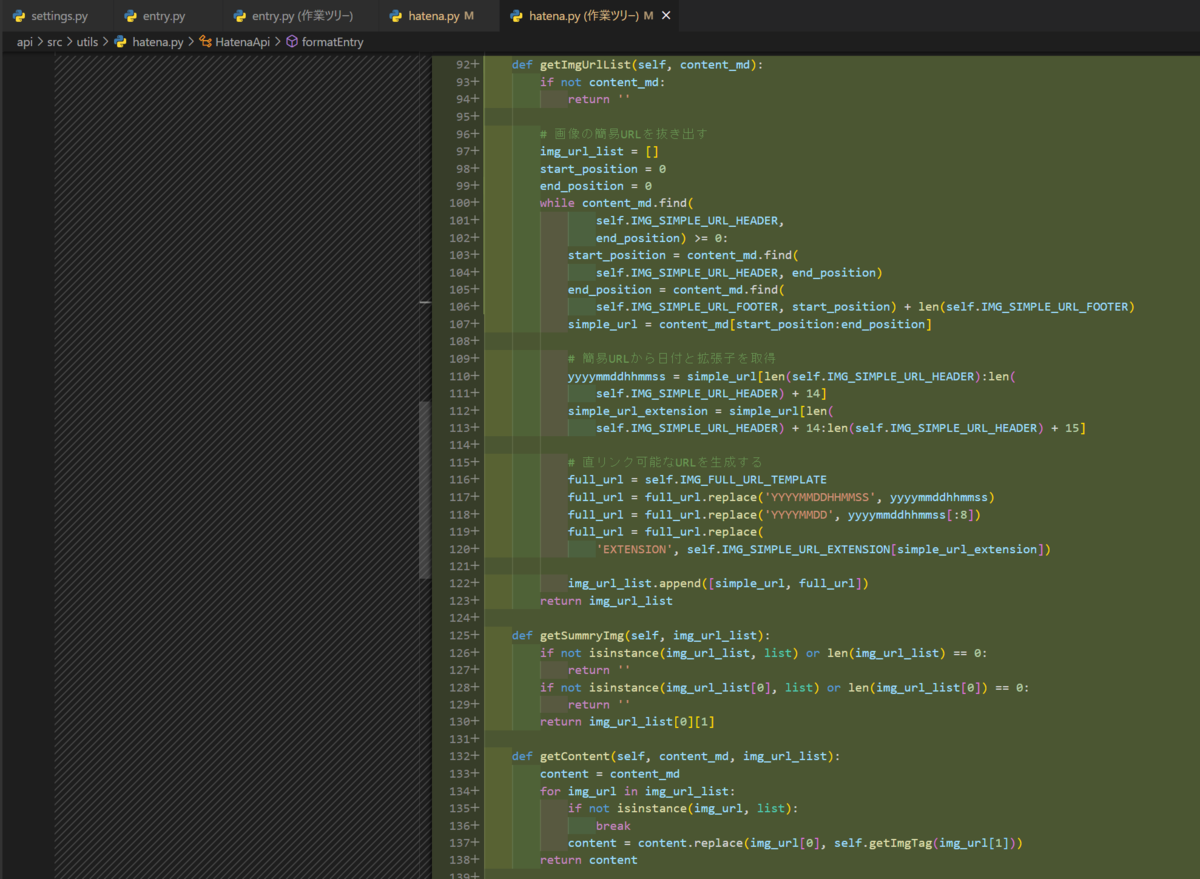
def getImgUrlList(self, content_md):
if not content_md:
return ''
# 画像の簡易URLを抜き出す
img_url_list = []
start_position = 0
end_position = 0
while content_md.find(
self.IMG_SIMPLE_URL_HEADER,
end_position) >= 0:
start_position = content_md.find(
self.IMG_SIMPLE_URL_HEADER, end_position)
end_position = content_md.find(
self.IMG_SIMPLE_URL_FOOTER, start_position) + len(self.IMG_SIMPLE_URL_FOOTER)
simple_url = content_md[start_position:end_position]
# 簡易URLから日付と拡張子を取得
yyyymmddhhmmss = simple_url[len(self.IMG_SIMPLE_URL_HEADER):len(
self.IMG_SIMPLE_URL_HEADER) + 14]
simple_url_extension = simple_url[len(
self.IMG_SIMPLE_URL_HEADER) + 14:len(self.IMG_SIMPLE_URL_HEADER) + 15]
# 直リンク可能なURLを生成する
full_url = self.IMG_FULL_URL_TEMPLATE
full_url = full_url.replace('YYYYMMDDHHMMSS', yyyymmddhhmmss)
full_url = full_url.replace('YYYYMMDD', yyyymmddhhmmss[:8])
full_url = full_url.replace(
'EXTENSION', self.IMG_SIMPLE_URL_EXTENSION[simple_url_extension])
img_url_list.append([simple_url, full_url])
return img_url_list
def getSummryImg(self, img_url_list):
if not isinstance(img_url_list, list) or len(img_url_list) == 0:
return ''
if not isinstance(img_url_list[0], list) or len(img_url_list[0]) == 0:
return ''
return img_url_list[0][1]
def getContent(self, content_md, img_url_list):
content = content_md
for img_url in img_url_list:
if not isinstance(img_url, list):
break
content = content.replace(img_url[0], self.getImgTag(img_url[1]))
return content
def getImgTag(self, img_url):
return self.IMG_FULL_URL_HEADER + img_url + self.IMG_FULL_URL_FOOTER
def getHatenaApiFirstUrl(self, action):
url = [
self.HATENA_API_URL_HEADER,
self.HATENA_API_USER,
self.HATENA_API_BLOG,
self.HATENA_API_URL_FUTTER,
action
]
return os.path.join(*url)
def getHatenaApiNextUrl(self, hatenaApiEntries):
url = ''
links = self.getDictValue(hatenaApiEntries, ['feed', 'link'])
if isinstance(links, list):
for link in links:
if self.getDictValue(link, ['@rel']) == 'next':
url = self.getDictValue(link, ['@href'])
return url
def getHatenaApiAuth(self):
return (self.HATENA_API_USER, self.HATENA_API_KEY)
def getDictValue(self, dictData, keys, emptyValue=''):
for key in keys:
if isinstance(dictData, dict):
if key in dictData:
dictData = dictData[key]
else:
return emptyValue
return dictData
おわりに
せっかく今回URL変換したのに、詳細画面を実装してないから最終確認できない!
はやめに詳細画面実装したいなー
ではでは今日はこの辺で!ちゃお~~~!
小村のポートフォリオサイト開発(15) Axiosを使用したAPI呼び出し
こんばんは、小村だよ!
今日も下記のポートフォリオサイトを構築していくよ
- サイト:Little Village
今回は久しぶりにUI側を触るよ!
ここまで書いてきたAPIをついにUI側から呼び出しちゃおうと思います!
目次
- Axiosの利用
- CORSエラーを解消する
- トップページに表示
記録
Axiosの利用
ではでは、APIをUIから呼び出していきまっしょい!
-
- このサイトおしゃれですね。ポートフォリオサイト自体の参考にもよさげ
Nuxt.jsからAPIを呼ぶ際、Axiosというライブラリを使うことが多いです
Nuxt.jsでプロジェクト作成時に、私はAxiosにチェックを入れたのでばっちり導入済でした!
 |
じゃあさくっと動作確認用のコードをUI側に書いてさくっと実行しよう!
ほんとに動作確認のためだけのコードを書いたので実行!
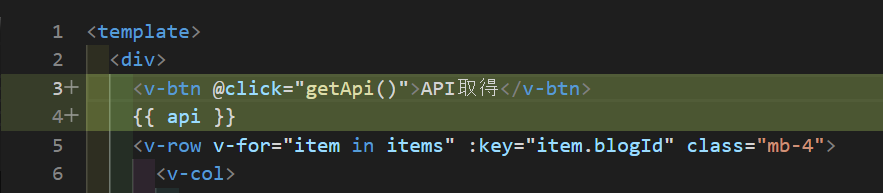 |
 |
 |
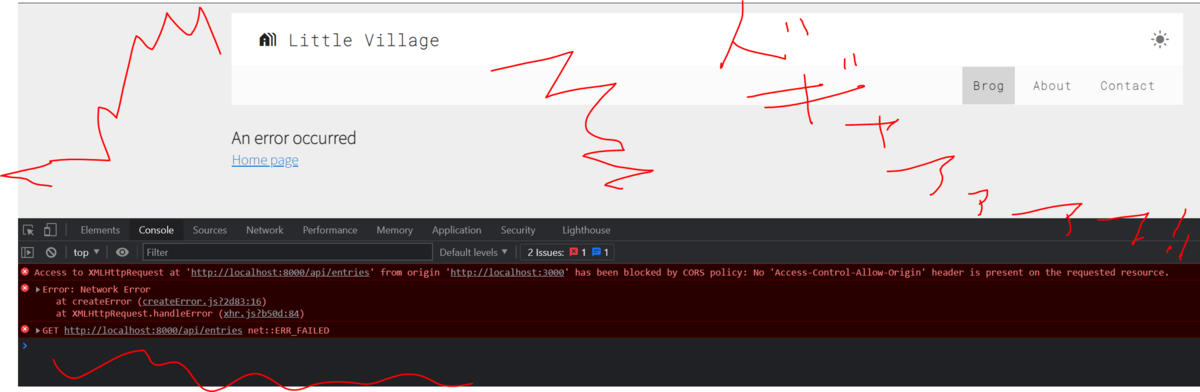 |
エラーやんけ!!!!!!
びぇ~~~~ん!!!どらえも~~~ん!!!
CORSエラーを解消する
参考:【解決済】Docker上のNuxtでaxiosのCORSエラーにハマりまくった話
解消方法は下記の2つがあるみたいです
メッセージの通りヘッダに
Access-Control-Allow-Originを付けるプロキシを設定する
今回は参考サイトの通りproxyを設定してみましょう。
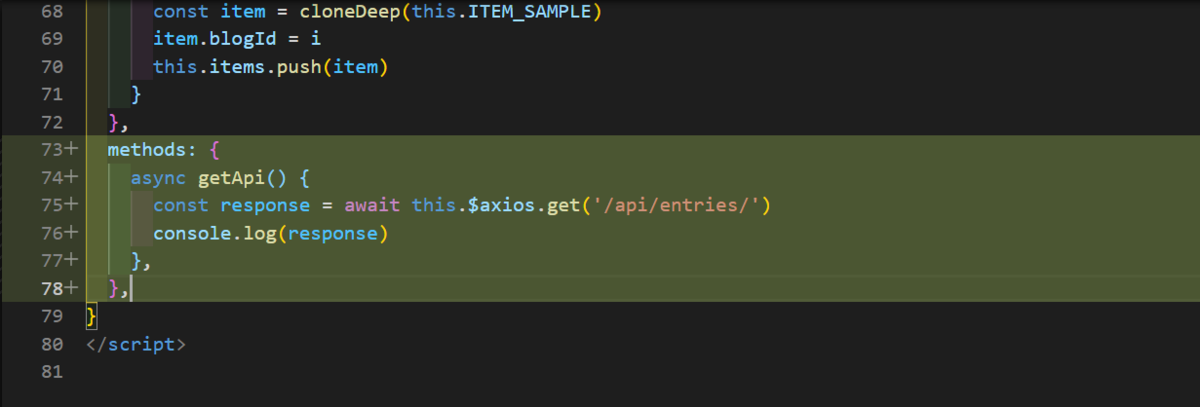
nuxt.config.jsを開き、下記の通り変更します
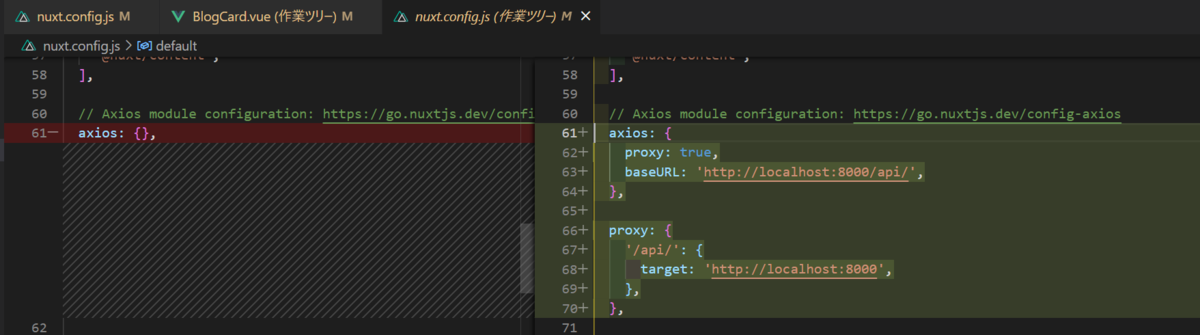 |
 |
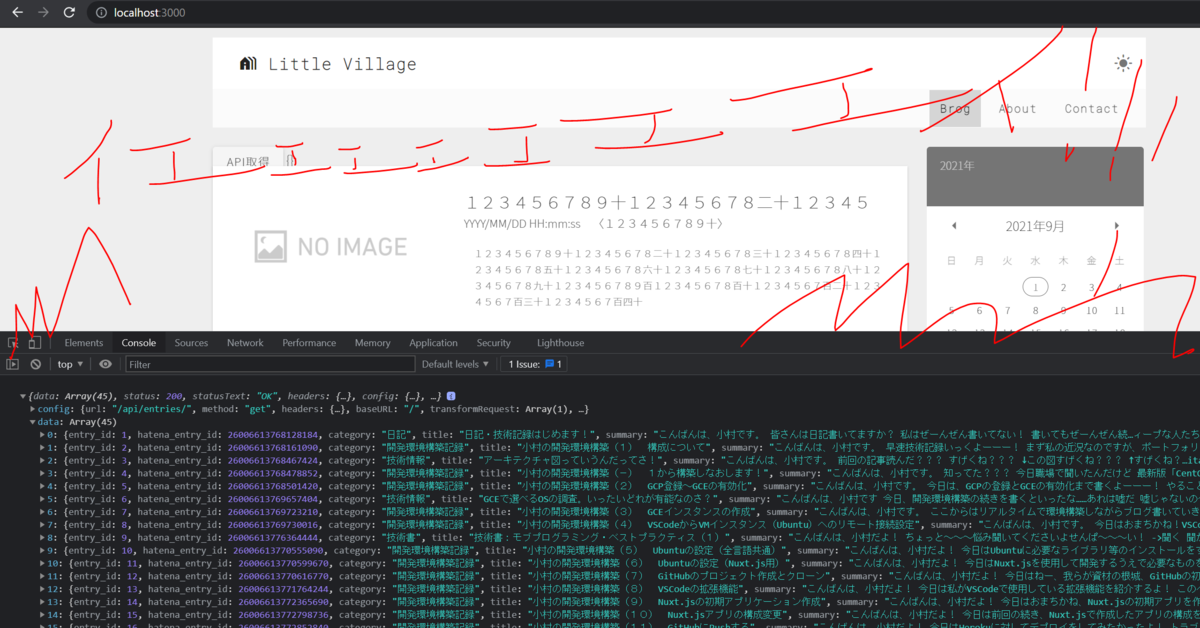 |
ひゃっほぉぉぉぉおおおおお!!!!
無事取得できました!!!!!!!!!!
トップページに表示
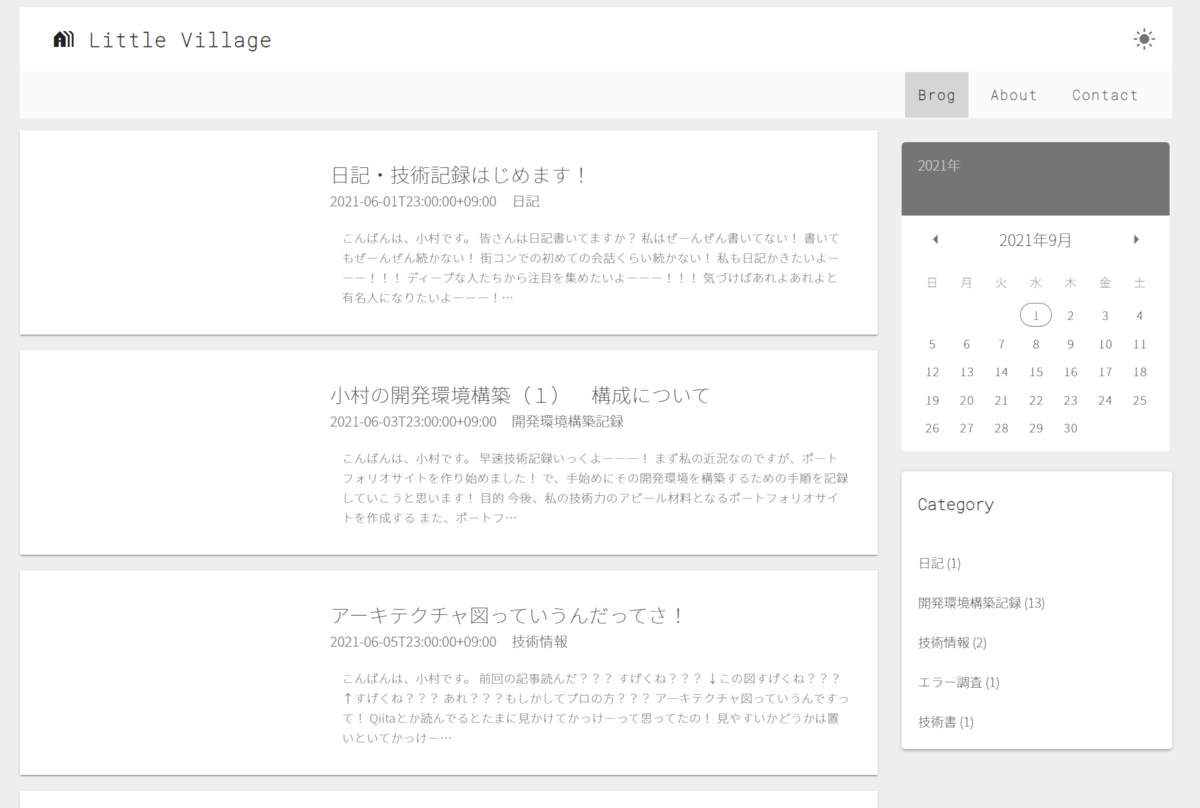
せっかく取得できたのでサイトに表示してみます!
色々エラーと格闘して最終的にこんな感じになりました!
 |
 |
おわりに
今日はこれでおしまい!
やーーーっとスタートラインに立った感じですかね!
こうやって日を置いてみるとサイトが物足りないな……
色々やること浮かんできますが、一つずつかたずけていきましょう!
ではでは、ちゃお~~~!